AIプロジェクトを推進する上で「責任と権限」に関して事前に把握しておきたいポイント
本ページに記載していた内容を下記のNoteに移行しました。よろしくお願いいたします。 note.com
Google Fit Platformについて調べてみた
Google Fitについて

@yutakikuchi_です。 今日はGoogle Fit Platformを利用してできることを調べてみました。Google Fitは言うまでも無くGoogleが提供するFitnessアプリで2014年から公開されています。また2021.11.04現在、Google Fitをスマートフォンのアプリとしてインストールすることで、アクティビティとしての毎日の目標、歩数計測、ハートポイント(強めの運動)、消費エネルギーなど、管理することができます。2021.11月において、Androidの一部の端末(Pixel)では、スマートフォンのカメラ機能で、呼吸数や心拍数の確認をすることができます。ちなみに、僕はGoogle Pixel 4aの保有者であり、購入時からGoogle Fitはプリインされていたと思います。
また、最近ではNianticが出した新しいARゲームのPikmin BloomでもGoogle Fitのinstallが必要であり、Google Fitがもしかしたら更に注目を集めるかもしれないですね。ちなみに、Pikmin Bloomは歩くことを重視したゲームのようです。
https://play.google.com/store/apps/details?id=com.nianticlabs.pikmin&hl=ja&gl=US topics.nintendo.co.jp
Google Fitは様々なアプリと連携することができるので、Google Fitに無いデータを他のアプリで取得して、それをGoogle Fit側で管理することもできたり。またその逆もできます。Google Fitが公式として連携しているアプリは下記のURLに記載されています。

引用 : https://play.google.com/store/apps/collection/promotion_3000e6f_googlefit_all
Google Fitのアプリでは取れないデータ、例えば日々の体重など、OMRONの体重計から取得、それをHealth syncアプリを経由してGoogle Fit側で一元管理するなど、複数のアプリを使い回すとそれぞれのアプリで取ったデータが一元管理できます。もちろん睡眠時間などのデータも他のアプリと連携することで取得可能です。下記のHealth syncはGoogle Fitの公式で連携アプリとして掲載されています。
Health Sync - Apps on Google Play
Google Fit Platformについて
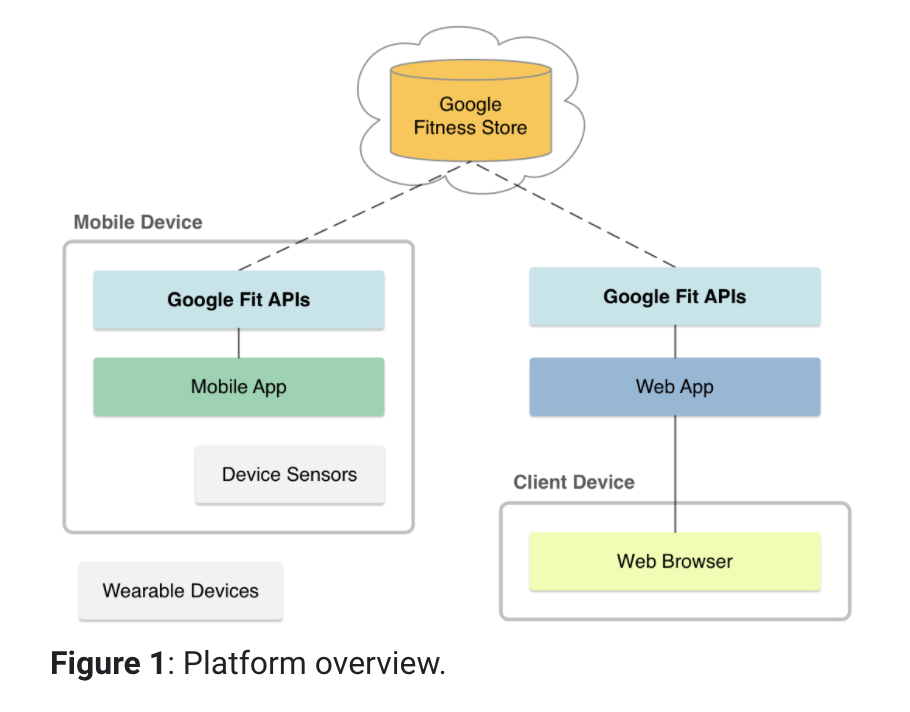
引用 : https://developers.google.com/fit/overview
Google Fit PlatformはGoogle Fitの裏側の仕組みと一言でいると思いますが、下記の4つの機能で成り立っています。主に開発者やサービス提供者がデータをGoogle Fit Platformに登録したり、データを呼び出したアプリケーションを作るための機構とも言えると思います。
- 様々なデバイスやセンサーから取れる個人のFitness関係のデータを管理するStore
- Fitness storeと簡単に連携するセンサーフレームワークを提供。下記のAPIと一緒に活用
- データへのアクセスの認証認可の仕組み
- AndroidのSDKやAPI、更にはWebのRestAPIの提供
Google Fit PlatformのAPIを使ってみる
https://developers.google.com/fit/rest/v1/get-started
こちらのGet startedに掲載されている手順で自身のGoogle Fitness Storeに登録されているデータを引っ張ってくる手順を記載します。手順の OAuth 2.0 Playground の項目を実施します。PlaygroundはOAuth認証が必要なAPIを簡単にお試しできるツールです。尚、僕は上でも書きましたがGoogle pixel 4aにGoogle Fitをインストールして、自身のGmailアカウントと連携をしているというのが実行の前提になります。またAPIのReference一覧は下記のURLに存在します。
https://developers.google.com/fit/rest/v1/reference
- Step 1 : Select & authorize APIs
- authorization コードの取得
- Step 2 : Exchange authorization code for tokens
- authorization コードからtokenへの変換
- Step 3 : Configure request to API
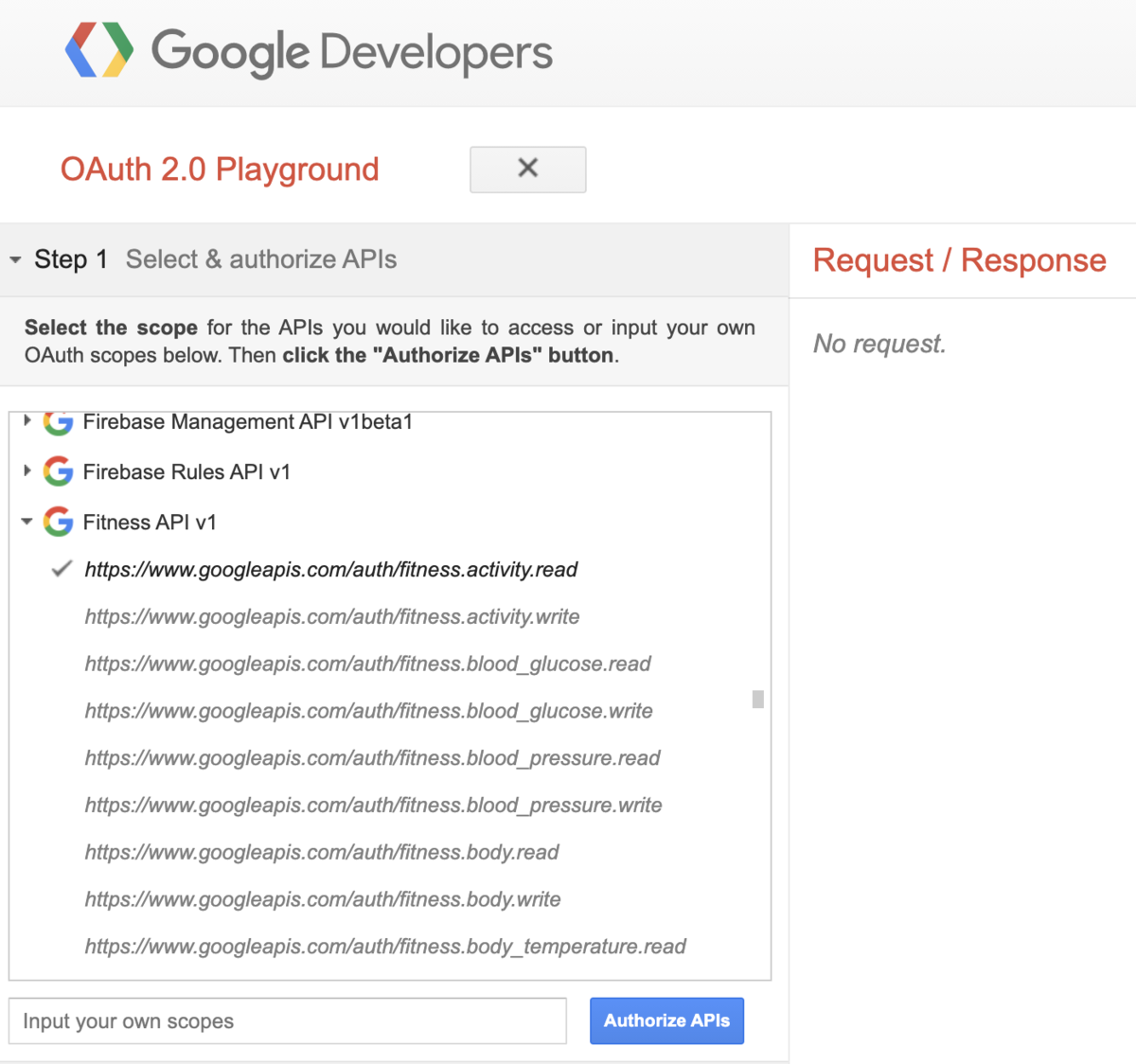
上を実行すると、Authorizeボタンの後にGoogleアカウントにGoogle Playgroundからのアクセスを求められるので、Continue/許可します。許可後にStep2として取得したauthorization コードから Refresh token とAccess tokenの2つを取得します。Step3の画面でAPIのEndpointを入力すると、その際に取得したAccess Tokenを利用しながら、HTTP GETで次のURLにRequestを送るように設定します。 Google FitのAPIとして、詳細のデータを取得する際はDatasourceの中にあるDatasetへのアクセスが必要なので、Datasetの取得には2段階のAPI実行が必要となります。
- Datasource一覧の取得
https://www.googleapis.com/fitness/v1/users/me/dataSources
- Dataset一覧の取得
https://www.googleapis.com/fitness/v1/users/userId/dataSources/dataSourceId/datasets/datasetId
Step3を実行するとAPIから200OKのresponseが返ってきます。Response Bodyの中身はJsonなので、それを読み取ります。下記の dataStreamIdの値が実際のDatasetへのアクセスのURIになるので、取得して次のAPIにRequestを送ります。
{ "dataQualityStandard": [], "dataType": { "field": [ { "name": "steps", "format": "integer" } ], "name": "com.google.step_count.delta" }, "dataStreamName": "estimated_steps", "application": { "packageName": "com.google.android.gms" }, "dataStreamId": "derived:com.google.step_count.delta:com.google.android.gms:estimated_steps", "type": "derived" },
上で取得したdataStreamIdを基に、実際のDatasetにアクセスをします。DatasetのEndpointの末尾に datasetIdとありますが、取得範囲を時間として示すstartTimeとendTimeをnanosecondsとして連結したstringのようです。datasetIdというパラメータの名前からは想像できない、ちょっと分かりづらいですね。ここでは 1635735600000000000-1635908400000000000 として指定します。
Dataset identifier that is a composite of the minimum data point start time and maximum data point end time represented as nanoseconds from the epoch. The ID is formatted like: "startTime-endTime" where startTime and endTime are 64 bit integers.
Google playgroundのStep3のURLを上記ものに変えて実行します。※末尾のdatasetIdは自身での書き換えが必要になりますので、ご注意ください。上のRequestはstep_count.deltaを取得するものになるので、これで特定nanoseconds間の歩数を配列形式で受け取ることができます。ちなみにstep_count.deltaの説明は下記にあります。
https://developers.google.com/fit/datatypes/activity#step_count_delta
{ "minStartTimeNs": "1635735600000000000", "maxEndTimeNs": "1635908400000000000", "dataSourceId": "derived:com.google.step_count.delta:com.google.android.gms:estimated_steps", "point": [ { "modifiedTimeMillis": "1635738581776", "startTimeNanos": "1635735582759950932", "endTimeNanos": "1635735642759950932", "value": [ { "mapVal": [], "intVal": 3 } ], "dataTypeName": "com.google.step_count.delta", "originDataSourceId": "raw:com.google.step_count.cumulative:Google:Pixel 4a:xxxxx:Step Counter" }, { "modifiedTimeMillis": "1635738581776", "startTimeNanos": "1635738494664463688", "endTimeNanos": "1635738554664463688", "value": [ { "mapVal": [], "intVal": 4 } ], "dataTypeName": "com.google.step_count.delta", "originDataSourceId": "raw:com.google.step_count.cumulative:Google:Pixel 4a:xxxxx:Step Counter" },
以上がGoogle Fit Platformについて調べて触ってみた内容になります。Google Fit PlatformのAPIを活用すると様々なヘルスケアアプリが作れそうですね。
参考リンクのまとめ
「お金は銀行に預けるな」を改めて読んで重要だと思うポイント
")
@yutakikuchi_です。2007年に発売された勝間和代さんの「お金を銀行に預けるな」を14年ぶりに読んでみましたが、改めて気づきを多く与えてくれる一冊でした。名著です。日本人の金融リテラシーの低さに警告を出すような本となっていますが、金融リテラシーの必要性から、具体的な実践までの話が纏められています。僕自身も14年前、当時社会人1年目のときにこの本を読んでみて、それまでは遊び感覚で投資していたことから、少しずつ積み立て投資信託や株の運用を実践するようになりました。「お金を生み出すのはお金である」、更には「金利は複利」なので、投資をできる限り早くしたほうがx年後に差が大きくなる、「できる限り早めに始めたほうが良い」という点を気づかせてくれる一冊です。以下は具体的に学びを得たポイントです。
- 日本は欧州と比べると圧倒的にリスク資産を持っている保有率が低い。
- 2007年の本の発売当初は日本がリスク資産4.4%に対して、アメリカは24.6%
- リスク資産の保有率の差はどこから来るのか?
- 金融リテラシーの差が大きいのは、日本では学校教育・家庭教育で金融リテラシーが軽視されてきた。また社会人になると仕事が忙しくて、金融リテラシーを身につける暇がない
- リスクを取るということは計算とコントロール可能なこと。計算もできず、コントロール不可能であればそれはギャンブル
- 私達が高いリターンを求めない、その流れからお金が金利の安い銀行や企業に預けられ、国などに貸し出された結果効率的ではない投資が生まれた。日本の金融資産の運用は一人一人がリスクを回避した結果、国全体として過度なリスク投資を生むことになり、それが自分たちの生活のしわ寄せを生んだと言える
その他、資産運用のための初心者でもできるノウハウなども書かれています。
参考までに、上の本は2007年の初版で、時間が経っているため、どれぐらい金融資産の構成に変化が出てきているかというと、未だに日本の場合は現金・預金が大半で、リスク資産は15%程でしょうか。少しずつリスク資産率が増えてきているものの、アメリカと比べると半分以下という実態。この20年間でアメリカは運用による家計金融資産を2.45倍としており、日本の倍以上の水準で資産運用ができている状態のようです。
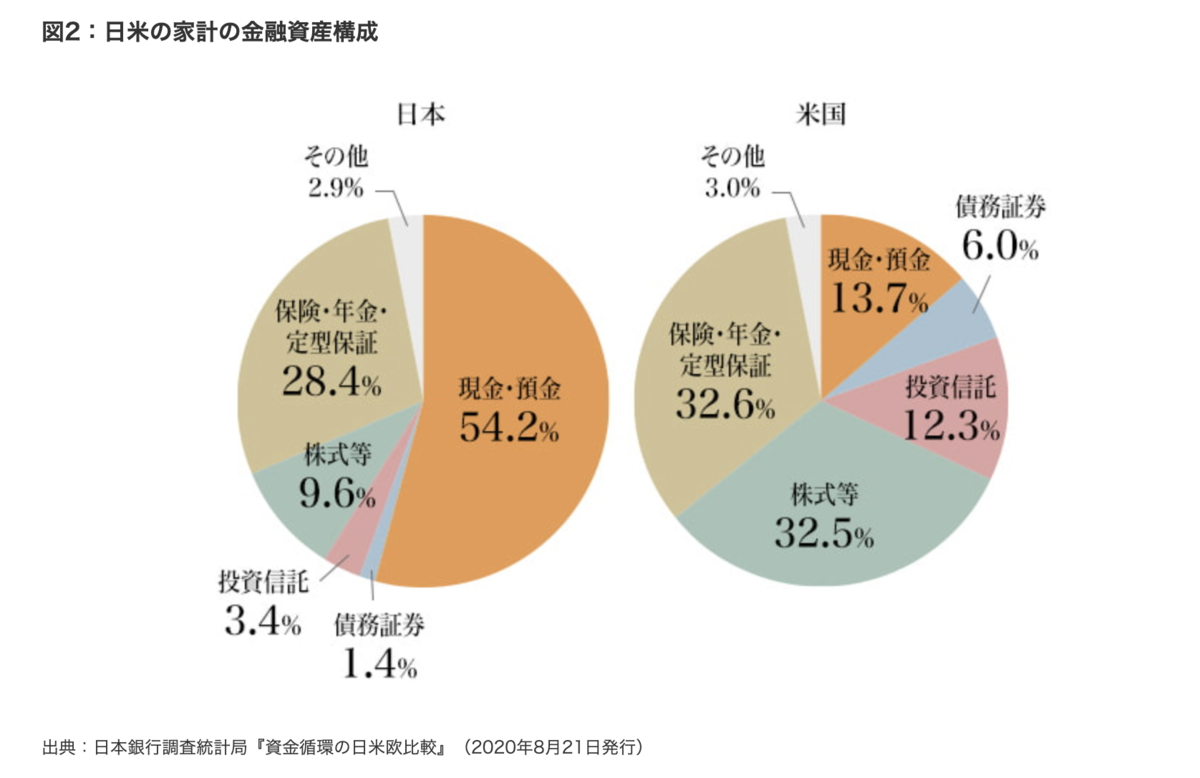
引用元 : www.nomura.co.jp
経営者になるためのノート
![経営者になるためのノート ([テキスト])](https://m.media-amazon.com/images/I/21OIhMFu5cS._SL500_.jpg "経営者になるためのノート ([テキスト])")
@yutakikuchi_です。 ファストリの柳井さんが2015年に書いた「経営者になるためのノート」という本、オススメです。本の分量自体は短いですが、センテンスとして重たい内容が沢山ある印象です。僕自身も過去に3社なんちゃって経営やってましたが、本当のプロ経営者の考え方・意識を参考にするために読んでみました。(残念ながらkindle版は無く、通常の本として購入が必要です。)下記は大切だと思った、共感した箇所のメモです。
- 序章 : 経営者とは
- 経営は「実行」である
- 経営に必要な4つの力
- 変革する力
- 儲ける力
- チームを作る力
- 理想を追求する力
- 第一章 : 変革する力
- 常識を疑って、常識に捕われない
- 顧客のことだけを見ている会社こそ未来がある
- 自分たちの基準として「世界で一番」の質の高さを目指すこと
- 本物は世界を貫く
- 会社を危険に晒したくないという志向性が会社を危険に晒す可能性が高い
- リスクが無いところに利益は無く、リスクが有るところこそに利益がある
- 第二章 : 儲ける力
- 本当の顧客満足とはお客様がほしいと思っているものを、お客様が想像しない形で提供する
- 第三章 : チームを作る力
- メンバーとは信頼こそが全て
- 「任せて任せず」
- 全てに対して細かい指示を出すのではなく、時には報告を求め本質的に達成すべきものとズレが生じていれば修正する助言や指導を行う
- リーダーが勝ちたいと思うことを強く意識する
- リーダーが挑戦しないところにメンバーの挑戦は無し
- 第四章 : 理想を追求する力
- 会社は使命感が重要であり、経営の戦略や意思決定が使命感によって行われていること。使命感にはずれたことはやらない
- お金を追いかけるとお金に逃げられる。使命感を追いかけるとお金がついてくる
「リスクが無いところに利益は無く、リスクが有るところこそに利益がある」、「リーダーが挑戦しないところにメンバーの挑戦は無し」とか心に刺さりまくりますね。当然利益を追うためにリスクを追うのではなく、リスクを事前に計算して、この範囲であれば対処可能として臨むことが重要ですね。
Adaloでアプリ上のデータを使ってQuickChartを動的に表示する
やること
@yutakikuchi_です。 AdaloとQuickChartを利用して、スマートフォンのアプリ開発として画面にQuickChartを埋め込み、アプリ上のデータを基にチャートを動的に表示することを行います。下記ではAdaloとQuickChartについて簡単に紹介、その後作業の流れを記載しています。
Adalo
- Freeで開始できるノーコードでWeb・スマートフォンネイティブアプリが作れるツールです
- ただし、apple store, google playへの公開は有償版に入らないとできません
- UI Componentがテンプレート化されていて、Adalo上でDrag & DropにてUIが作れます
- Adalo上ではWeb・ネイティブアプリの1ページずつがScreenという単位で管理されています
- Screenに対してComponent(Button, List, Form, Image...)などのパーツを紐付け、更にComponentに対してClickしたときにどういったActionを必要とするかを定義します
- Databaseというメニュー機能を利用して、Adalo上のデータ構造を定義し、各画面などから呼び出しを可能とします
QuickChart
- WebAPIとしてSimpleなChartを画像やpdf等の出力フォーマットで表示をしてくれます
- GitHub - typpo/quickchart: Chart image and QR code web API
- QuickChartはopensourceであり、自身の環境にホスティングすることも可能です
https://quickchart.io/chart?c={type:'bar',data:{labels:['Q1','Q2','Q3','Q4'], datasets:[{label:'Users',data:[50,60,70,180]},{label:'Revenue',data:[100,200,300,400]}]}}
Adaloで作るアプリにQuickChartを表示し、動的にコントロールする
以下の手順で行います。QuickChartの例として、Raderチャートを用いています。Raderには自身の健康状態を記載するイメージのものになります。Raderチャート上に出力するPlotデータはLogin中のUserのデータをdatabaseから引いてくる状態としています。ここでは詳細を記載しませんが、下記と同じことをやろうとした場合、databaseにdefaultで入っているUser collectionに対してpropertyを事前に追加しておく必要があります。
- QuickChart上でパラメータの確認と修正
- Adalo上で修正したQuickChartのURLを貼り付け
- Adalo上でアプリのパラメータとQuickChartを連携
QuickChart上でパラメータの確認と修正
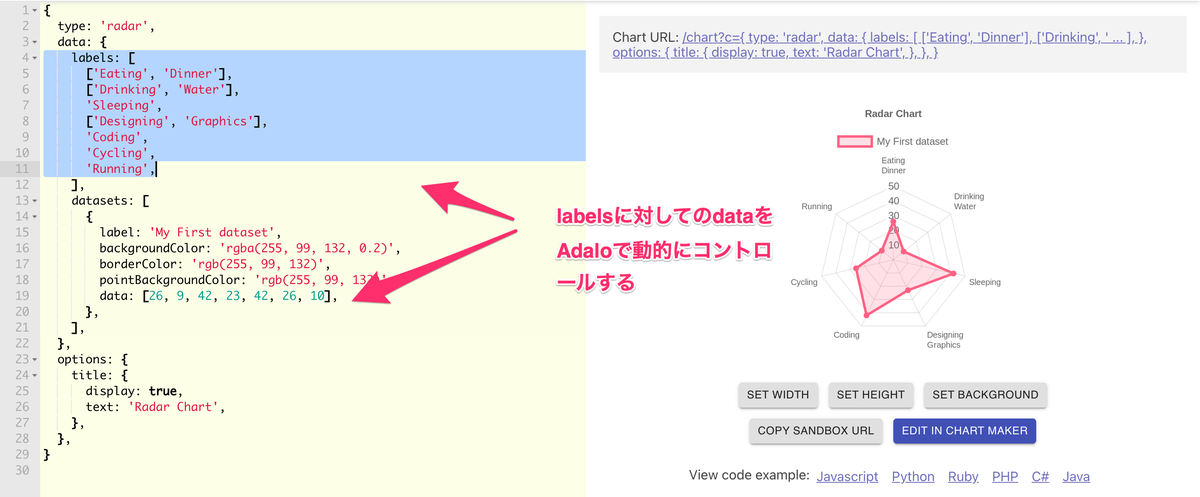
こちらの作業はQuickChart上でのものになります。
QuickChart上でRaderのsampleを表示すると、上の画像のように画面左にjson形式の項目を修正できるeditorが出てきます。ここで確認すべきなのはRaderチャートとして表示すべきlabelsとそのlabelに対して表示するdataになります。dataは配列形式になっているので表示しているlabelとdataの順番が一致している必要があります。Adaloと連携をする際はこのdataの配列に対して、Adalo上のデータを連携するための記載をする必要があります。
画面右上に表示されるQuickChartのURLをコピーして次の作業に移ります。
Adalo上で修正したQuickChartのURLを貼り付け
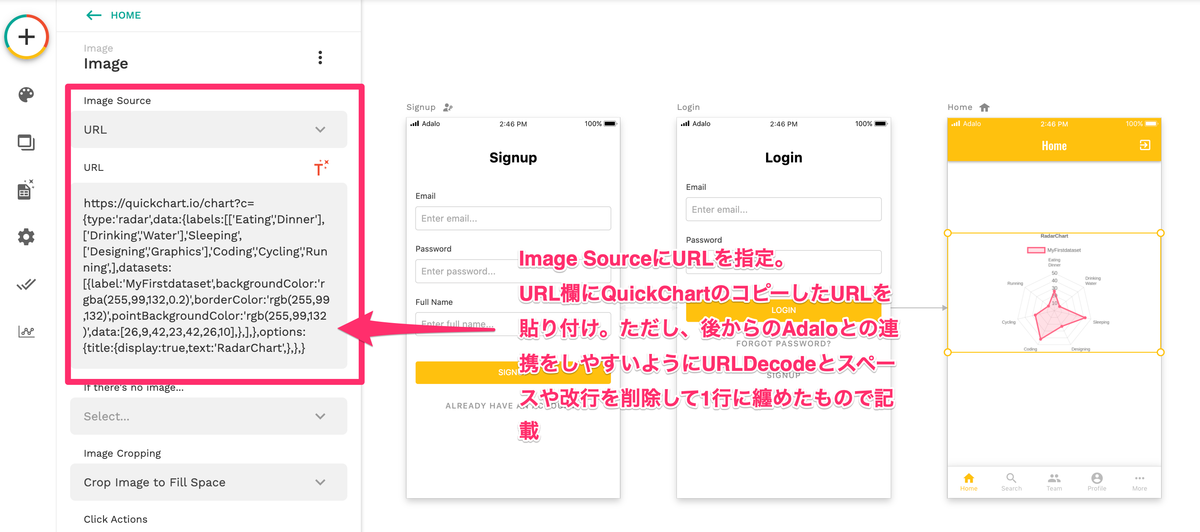
こちらの作業はAdalo上でのものになります。
上のキャプチャではHOMEのスクリーンに対して、imageのcomponentを用意し、componentのimage sourceをURLに設定。 更に、URLの入力欄にQuickChartで出力したchartの画像を出力するurlを貼り付けます。そうすると、画像一番右のようにQuickChart上で見たRaderチャートが表示されます。urlの貼り付けについて、通常だとjson形式の箇所に対してURLEncodeが掛かった状態でコピーされていますが、そのまま貼り付けてしまうとURLEncodeが掛かったままでAdalo上のデータ連携の修正を行う必要があり、作業が困難になります。そこで、Adalo上で後から編集しやすいように、URLDecode、更にはスペースや改行を削除した1行になっているもので貼り付けをし、Adalo上のデータとの連携修正をしやすくします。
Adalo上でアプリのパラメータとQuickChartを連携
こちらの作業はAdalo上でのものになります。
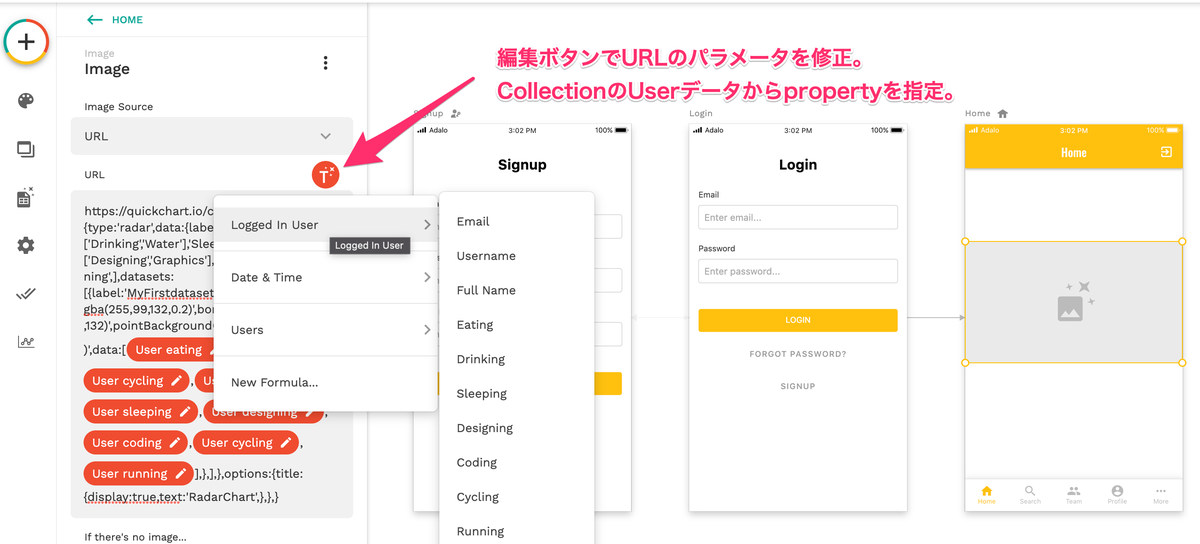
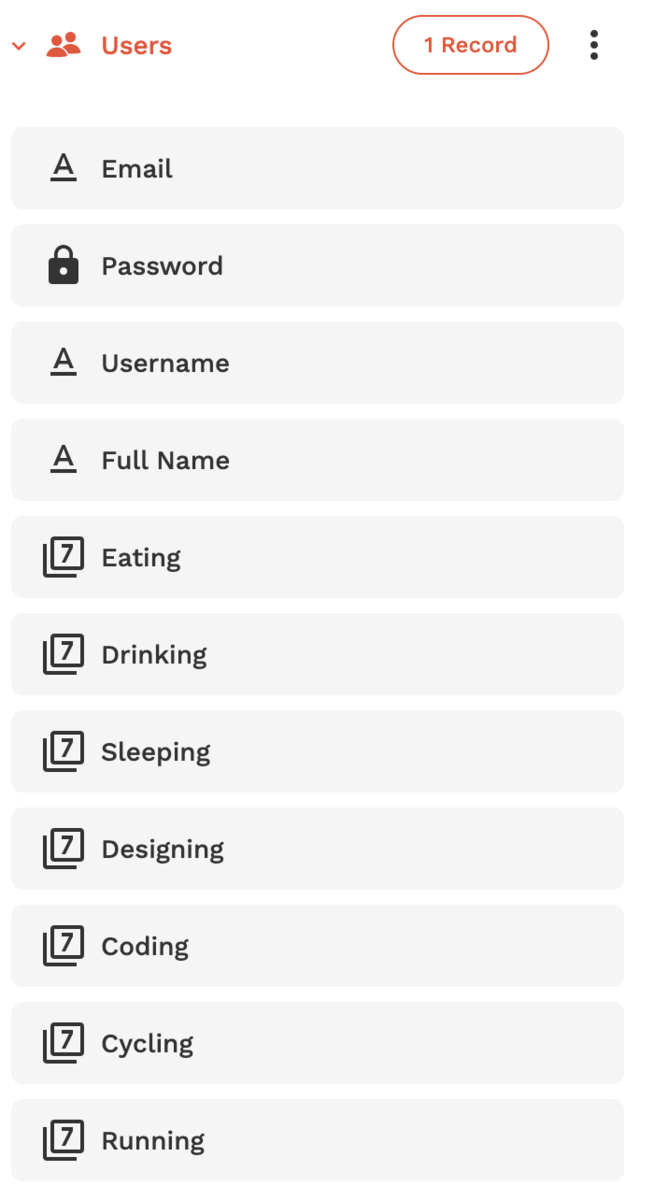
Adaloに貼り付けたURLの中でChartをPlotするためのdataという配列が有りましたが、そこを修正します。dataの配列に記載するものはDatabaseに入っているUser collectionの中のpropertyから参照する形にします。(事前に下記図のようにpropertyを追加しておく必要があります。)
AdaloのURLの右に表示される編集ボタンで、data配列の先頭から一つずつUser collectionのpropertyを指定していきます。指定すると、User eating のようにAdaloが持つDatabaseの項目で書き換える設定が完了していることを示します。
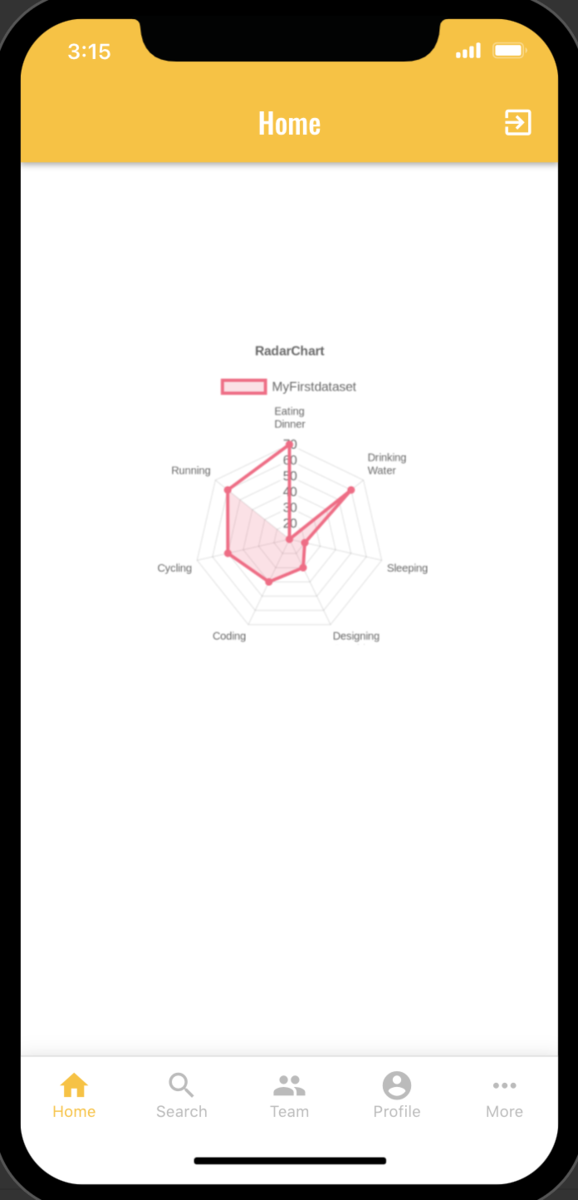
以上で、一通りの作業は完了になります。Adaloのツールの画面右上に出ている Preview というボタンを押すとLoginしているUser collectionからデータを引っ張ってきた状態でRaderチャートが表示されます。これで各UserごとのデータをRaderチャートとして動的に出力することが可能になりました。Adalo非常に便利ですね。ここでは記載をしていませんが、外部APIとの連携やWebViewも簡単にできそうなので、そこも試してみたいと思います。
高く飛ぼうぜ
海外ドラマ シリコンバレーを再度見ている。シリコンバレーとは音楽の著作権を検索するために、データの圧縮アルゴリズムを開発し、仲間と共にPied Piperという会社を起業をする話し。何気ないドラマのシーンやセリフがWebプロダクト開発や起業に携わったことがある人は共感できること多数という感じ。
今日はシーズン1の第1話、実用最小限の製品の中のやり取りで、データ圧縮アルゴリズムを開発したプログラマーでありPied Piperを起業するリチャードとそれを支えるインキュベーターのアーリック会話に注目したい。実現したいことシーズン1の第1話ではリチャードには大手IT会社に数百万ドルで買収されるか自分たちで起業をするかを迷い、勇気のある後者を選択している。
買収されると自身や開発に携わったメンバー、更にはインキュベーターのアーリックも富を得る形になるが、リチャードが自分で起業をするという思いをアーリックや他のメンバーに告げる。その話しを聞いたときのアーリックの発言。直近の富を取るより、ものを創りそれを見届けたいという思いでリチャードの意思に賛同する発言。(ちなみにアーリックは過去にアビアトというプロダクトを売却し富を得ているが、こころのどこかで後悔をしている) その発言を下記に記載。
- アーリック : 「売らなかったらとかんがえちまう、心残りだ」
- アーリック : 「だから言うよ お前は俺に似ている」
- アーリック : 「何かを創り 見届けたいんだ」
- リチャード : 「即金の100万を蹴っても許す?」
- アーリック : 「許すどころか ワクワクしている」
- アーリック : 「高く飛ぼうぜ パートナー」

起業を選択したリチャードの勇気のある決断、それを勇気づけてくれたアーリック。アーリック最高かよ...。「高く飛ぼうぜ パートナー」このシーンを見ると何度も心を震わせられるので、第1話を是非多くの人に見てほしい。
ユニットエコノミクスの定義

ユニットエコノミクスとは
Startupが事業やプロダクトの拡大前に一人もしくは一社獲得した場合に利益を出すことが可能かどうかを表す指標がユニットエコノミクスである。ユニットエコノミクスが利益を出している状態であり、Startupが戦略として事業とプロダクトを拡大するのであれば利益額もスケールアップする。しかし、仮にユニットエコノミクスが基準ラインを達成されていなく、拡大を試みると赤字額を膨らませてしまう。ユニットエコノミクスが健全で無い状態は提供価値の価格とコストが見合っていない証拠。よってこの場合は事業の収益構造を見直す必要がある。
ユニットエコノミクスの計算は次の変数が利用される
ユニットエコノミクスの計算式は下記で示される。(ただし、LTVなどは展開したい事業によって意味合いが異なる場合がある)
LTV < CPA(CAC)となってしまうと、ユニットエコノミクスは1より小さい値となってしまい、この場合は拡大をしない判断をする。一般的にはユニットエコのミスクの値となるLTV/CPA(CAC)が3以上を出している場合が望ましいとされる。 3に達していない場合はChurn Rateを如何にさげるためのプロダクト改善やSuccessチームの体制構築、もしくはマーケ費用を投下した顧客獲得効率を上げる(CPC,CACを下げる)活動を必要とされる。
また、ユニットエコノミクスだけではなく、拡大時に顧客獲得に払ったSales & Marketing費用の回収期間(PayBack Period)も見定めなければならない。回収期間は短ければ短いほどよいが、一般的には6〜12ヶ月であれば望ましい状態とされている。 CPA(CAC)が小さく、MRRが大きくなれば回収期間の値も短くなる。
: 顧客獲得に払ったSales & Marketing費用の回収期間