良いイシューの3つの条件

「イシューからはじめよ」 を再度読み直ししている。仕事においてプロセスを見直したい人、生産性を上げたいと思っている人にはオススメ。
生産性を 生産性 = アウトプット / インプット = 成果 / 投下した労力・時間 と定義した場合、バリューのある仕事にフォーカスすべきであり、バリューのある仕事とはイシュー度と解の質の2軸から成り立つ。この本の中で書かれている重要なポイントとしては、ひたすら課題を解いて解の質を上げることをするのではなく、まずはイシュー度(課題の質)を上げること。最初にすべきこととして課題を解くことではなく、課題をちゃんと見極めることの重要性が書かれている。僕個人の経験としてもビジネスにおいては課題解決を如何に効率よく行うか、また解決手段をいち早く提示・構築できるかにバリューとしての焦点が当たりがちだが、本当に解くべき課題なのか、その課題設定が間違っていたら最初に立ち返ってやり直すような習慣が必要だと感じることが多い。
本の中に書かれていた良いイシューの3つの条件として下記が定義されている。
- 本質的な選択肢である
- その答えが出ると今後の検討方向性に大きく影響を与える
- 深い仮説がある
- 一般的に信じられている信念や前提を突き崩せないかを常に考える
- 共通性、関係性、グルーピング、ルールの発見により検討対象を新しい構造として説明すること
- 答えを出せる
- 既存のやりかた・技術でも答えがだせるもの
またこういった良いイシューを特定するための行動として、何のフィルターも通っていない生の情報である一次情報を集めるために現場で起こっていることを聞くこと。そしてその情報をもとにスキャン(調べる)活動を行うこととされている。
全ての内容を読まなくても、序章・第一章の合計70ページでも非常に価値が高い一冊である。
経営とエンジニアリング
経営とエンジニアリング
会社経営とエンジニアリングは似ているという話。
ITエンジニアの多くの方なら、解きたい課題解決のために製品開発をする、開発のためにロードマップを書き、実現するためのスケジュールを引く。開発項目を更に細かいissue化し優先度を決め、それを解くためのアルゴリズムを構築する。この手順はおそらく誰もが経験しているだろう。この手順、それはまさしく経営も一緒。
経営は会社が実現するVisionを定義、Visionを実現するために必要なモノ・人・金を管理した事業構築を目指す。事業の中身は常に仮説検証の連続であり、検証と実行のために必要な短期・長期のロードマップを書き、スケジュールを引く。経営として解決しなければならない特にモノ・人・金に関する項目をissue化し優先度を決め、それを解くための手段を構築する。
何よりも経営として自社のビジネスモデルを構築するのはエンジニアがアルゴリズムを書く作業と非常によく似ている。エンジニアリングの観点でも目的を達成するためには最小限のソースコードで実現するために、OSSを活用したり、同じstepのコードを書かないようライブラリにして効率化、また外部サービスのWebAPIを利用したりなど、最小限の労力で最大限の効果を得られるよう考慮されている。
経営も同様。最小限の労力で最大限の効果が得られるよう経営アルゴリズムを書いている。自社の事業が最大限に成長するために、自社で作るモノを明確化、それに必要な人を採用、予算をかける。解きたい課題に対して再現性を生み出すために製品化したり、製品営業をパッケージ化して効率化を図る。実現したい事業の全てを自社で作れない場合は外部の企業との連携をするなど。
ね、会社経営とエンジニアリングは似ているでしょ。似ていない部分も多いはずだけど、エンジニアの方でも経営に携わるというキャリアパスは大いに有り得ると思います。
AIのモデルをオンライン環境で評価する方法
はじめに
昨年末にABEJA Advent Calenderで「AIをシステムに実装する方法」というタイトルでシステムエンジニアの方向けにQiitaで書いたところそれなりに反響があったので、今回はAIのモデルをオンライン環境で評価する方法の部分についてより詳しい内容を書きたいと思います。ここで言うオンライン環境とは製品のProduction環境、特にオンラインで実行できる環境という形で読んでいただけると良いと思います。内容をBlogからQiita側に移しましたので、下記リンクを参照ください。
AIをシステムに実装する方法
ABEJA Advent Calendar 2019
ABEJA Advent Calendar 2019の最終日の投稿をQiitaに書きました。こちらのBlogからリンクだけ張っておきます。僕の投稿は AIを活用したいが、何から始めたら良いか困っているシステムエンジニアの方 向けの内容になっています。ABEJA Advent Calendarも非常に内容が濃いものになっていますので、是非御覧ください。
Raspberrypi zero WとEdge TPUを活用した侵入者通知アプリを作る
やること
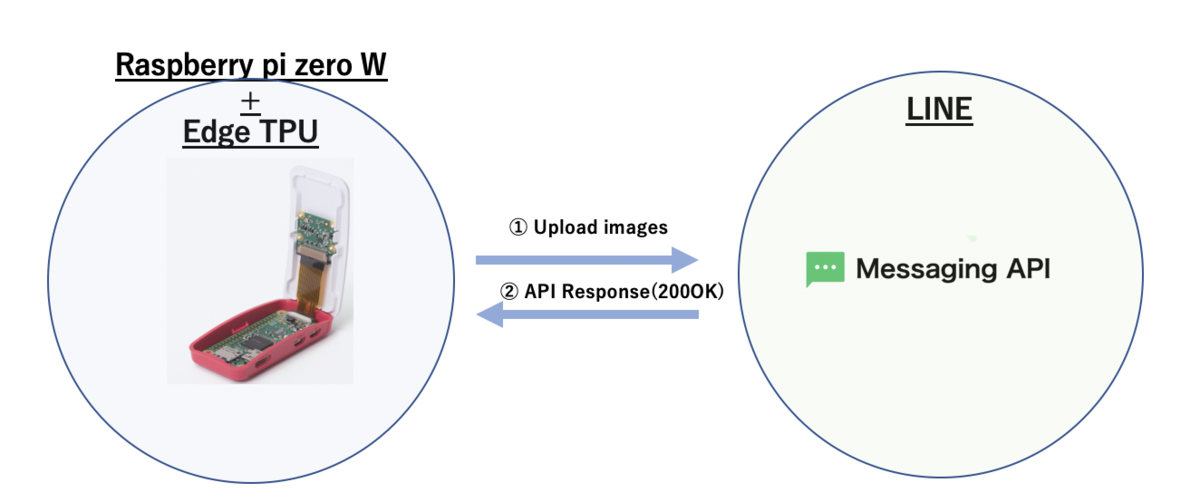
以前のBlog PostでRaspberrypi zeroとABEJA Platform(Cloud環境)を活用した侵入者通知アプリを作りました。解決したい課題としては、1階のマンションに住んでいる場合、庭・バルコニーへの不審者の立ち入りが気になります。そこで簡易的なRaspberrypiとLINE Botを利用し、簡易的な写真付きの侵入者通知アプリを作りたいと思いました。
前回はRaspberrypi側にcronで5秒間隔にて画像を撮影し、撮影された画像ををそのままABEJA PlatformのAPIへpostし、SSDにて人物検出を行いました。ただし、これには5秒以内に人がカメラの中に収まることを前提にしたものだったので、侵入者を見落とす可能性がありました。今回は人物検出をEdge側にてSSDで行い、リアルタイムで不審者を検出します。これはTPUがあるからこそ為せる技です。不審者を検出した場合のみLINE Botに通知し、常にAPIのcallのために外部通信を発生させる事無く、より効率的な構成にしようと思います。人物の検出はraspiのcamera moduleで行うため、事前に設定がonになっていること(vcgencmd get_camera コマンド)で確認をします。
RaspberrypiとEdge TPUの接続

今回使用しているのはRaspberrypi zero WとEdge TPUのUSB Acceleratorとなります。
- Raspberrypi zero Wはスターターキット : 4104円
- USB Accelerator : 9450円
- Raspiのcamera module : 1400円
だったので今回のハードの設定での 合計15000円 で構築している環境になります。上の写真のようにmicroB-USBの変換を用いて、USBのAcceleratorをRaspiと接続をしています。またraspberrypiのケースの中には既にcamera moduleが接続されており、ケースの中央の円からcameraが外向きに出ている状態です。
Raspberry Pi Zero W スターターキット--販売終了 - スイッチサイエンス Raspberry Pi Shop by KSY https://www.amazon.co.jp/raspberry-カメラモジュール-Raspberry-とケース500W画素-感光チップOV5647センサー/dp/B07NSS1QRW
実装する上で必要なもの
- Raspberrypi zero W
- Edge TPU(USB Accelerator)
- ABEJA Platform アカウント
- bitly アカウント
- LINE Developers アカウント
Raspberrypi側の環境設定
Raspberrypi zero Wにpyenvでpython 3.5.7を入れています。Defaultのsystemでのpythonは2.7.13になります。
pi@raspberrypi:~$ uname -a Linux raspberrypi 4.19.66+ #1253 Thu Aug 15 11:37:30 BST 2019 armv6l GNU/Linux pi@raspberrypi:~$ pyenv versions system * 3.5.7 (set by /home/pi/.python-version) 3.6.8 pi@raspberrypi:~$ echo $SHELL /usr/bin/zsh pi@raspberrypi:~$ vcgencmd get_camera supported=1 detected=1
Raspi側のpyenv設定とnumpy等のinstall
Raspiのdefaultのpythonは2.7.13なので、これを3.5.7に設定します。またnumpy, pillow, picamera, opencv-python, opencv-contrib-pythonm, opencv-contrib-python-headlessを必要とするのでpipでinstallしておきます。また最新のRaspiのOSディストリビューションなどを最新のものにします。これを怠るとedgetpu側でerrorを起こす場合があります。opencv関係のpackageを入れないと後ほどerrorが出るので、先に入れておきます。
pi@raspberrypi:~$ sudo apt-get update pi@raspberrypi:~$ sudo apt-get upgrade pi@raspberrypi:~$ sudo apt-get dist-upgrade pi@raspberrypi:~$ sudo apt install libhdf5-100 libharfbuzz0b libwebp6 libjasper1 libilmbase12 libopenexr22 libgstreamer1.0-0 libavcodec-extra57 libavformat57 libswscale4 libgtk-3 libgtk-3-0 libqtgui4 libqt4-test pi@raspberrypi:~$ reboot pi@raspberrypi:~$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv // 下記を追加 pi@raspberrypi:~$ vim .zshrc export PYENV_ROOT=$HOME/.pyenv export PATH=$PYENV_ROOT/bin:$PATH eval "$(pyenv init -)" pi@raspberrypi:~$ source .zshrc pi@raspberrypi:~$ pyenv install 3.5.7 pi@raspberrypi:~$ pyenv local 3.5.7 pi@raspberrypi:~$ pyenv global 3.5.7 // pipで必要なmoduleを追加 pi@raspberrypi:~$ pip install numpy pillow picamera opencv-python opencv-contrib-python opencv-contrib-python-headless requests pi@raspberrypi:~$ pip freeze certifi==2019.9.11 chardet==3.0.4 edgetpu==1.9.2 gi==1.2 idna==2.8 numpy==1.17.2 opencv-contrib-python==3.4.4.19 opencv-contrib-python-headless==3.4.4.19 opencv-python==3.4.4.19 picamera==1.13 Pillow==6.1.0 pygame==1.9.6 pyparsing==2.4.2 requests==2.22.0 scipy==1.3.1 svgwrite==1.3.1 urllib3==1.25.5
RaspiへのTPU Moduleのinstall
Edge TPUのModuleを上記リンクの内容に従ってinstallします。僕のRaspiはzero Wというタイプなので、EdgeTPU 1.9.2というModuleをinstallします。またinstall先が /usr/local/lib/python3.5/dist-packages/ 配下になるため、こちらをpythonpathに追加します。
pi@raspberrypi:~$ wget https://github.com/google-coral/edgetpu-platforms/releases/download/v1.9.2/edgetpu_api_1.9.2.tar.gz pi@raspberrypi:~$ tar xzf edgetpu_api_1.9.2.tar.gz pi@raspberrypi:~$ cd edgetpu_api pi@raspberrypi:~$ bash ./install.sh pi@raspberrypi:~$ vi ~/.zshrc //追記 export PYTHONPATH='$PYTHONPATH:/usr/local/lib/python3.5/dist-packages' pi@raspberrypi:~$ source ~/.zshrc
Google Colraのgitにあるexampeを実行してみる
github.com
上記githubに存在するexamples-cameraを実行してみます。git clone後にmodelファイルをdownloadする必要があるので、download_models.shを実行します。download後にclassify_capture.pyを実行するとraspiのcamera moduleで撮影されたstreaming動画をclassificationを行いますが、一定時間の動画を解析した後に Deadline exceeded のerrorで処理が途中で止まってしまいます。おそらく原因はUSBの転送処理の限界、もしくはTPUの電源の限界かと思います。(まだ正しい解決策が分かっていません)
pi@raspberrypi:~$ git clone https://github.com/google-coral/examples-camera.git pi@raspberrypi:~$ cd examples-camera pi@raspberrypi:~$ bash ./download_models.sh // 出力結果 ./mobilenet_v1_1.0_224_quant_embedding_extractor.tflite ./mobilenet_v2_1.0_224_inat_plant_quant_edgetpu.tflite pi@raspberrypi:~$ cd raspicam pi@raspberrypi:~$ python classify_capture.py // 出力結果 Inference: 19.25ms FPS: 12.2 61% jersey, T-shirt, tee shirt 5% sweatshirt 3% abaya Inference: 20.39ms FPS: 12.0 52% jersey, T-shirt, tee shirt 7% abaya 3% sweatshirt F /home/pi/edgetpu-ml-cpp-release-rpi0-1.9.2/darwinn/third_party/darwinn/driver/usb/usb_driver.cc:834] transfer on tag 1 failed. Abort. Deadline exceeded: USB transfer error 2 [LibUsbDataOutCallback]
不審者を検出し、写真をLINEに通知する
SSD modelファイルの指定


今回も簡易的なテスト通知を行う仕組みとします。上の画像のように家の中から外に向けてraspberrypiを固定し、常に監視している状態を作ります。
上述の ./download_models.sh を実行したことにより様々な学習済みmodelファイルがdownloadされています。今回人物検出に使うモデルはSSDを指定します。raspberrypi側のcamera module + SSDで検知した不審者の写真を都度LINEに通知し、証拠写真としても記録する事を試みます。 学習済みmodelのファイルは mobilenet_ssd_v1_coco_quant_postprocess_edgetpu.tflite、検出ラベルのファイルとして coco_labels.txt を利用します。 coco_labelsにはpersonも含まれているので、今回はこれを利用します。
pi@raspberrypi:~$ ls ../all_models | grep ssd mobilenet_ssd_v1_coco_quant_postprocess.tflite* mobilenet_ssd_v1_coco_quant_postprocess_edgetpu.tflite* mobilenet_ssd_v2_coco_quant_postprocess.tflite* mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite* mobilenet_ssd_v2_face_quant_postprocess.tflite* mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite* pi@raspberrypi:~$ ls ../all_models/coco_labels.txt ../all_models/coco_labels.txt pi@raspberrypi:~$ grep "person" ../all_models/coco_labels.txt 0 person
classify_capture.pyの修正と処理手順
https://github.com/google-coral/examples-camera.git こちらの examples-camera ディレクトリにある classify_capture.py を下記のように修正し、LINEへの通知を行います。※下記はテストコードであり、一度人物を検出した場合はexitさせています。
ちなみに処理手順は以下のものです。
- raspberrypiのcamera moduleでstreamingから画像をcapture。その際にはpythonのpicamera moduleを使用。 - Edge TPU上でSSDを実行し、人物判定確率が60%以上のものに関しては画像をアップロード。 - LINE Botに通知するためには参照可能な画像URLを必要とするため、ABEJA Platform Datalakeに人物判定された画像をアップロード。URLを取得。 - URLの短縮化。bitlyのAPIから取得。 - LINE Messaging APIに画像の短縮URLを含めたJsonのRequest BodyをPOST。 - LINEに不審者をリアルタイムで検出し、証拠画像付きの通知が流れてくる。
ABEJA Platform Datalakeへの画像upload
LINE Botに通知する画像は参照可能なURLである表現される必要があります。今回はABEJA Platform Datalakeを使用することにします。ABEJA Platform Datalakeに画像をpostするために、SDKをinstallします。Datalakeに画像をuploadするとdownload_urlを取得する事ができるので、LINEへの画像URL postのためにdownload_urlという属性を利用します。ソースコード上にABEJAのcredential情報を入力すれば下記の内容で画像がupload、download_urlが取得可能です。
pi@raspberrypi:~$ curl -s https://packagecloud.io/install/repositories/abeja/platform-public/script.python.sh | bash pi@raspberrypi:~$ pip install abeja-sdk pi@raspberrypi:~$ pip freeze abeja-sdk==0.2.12 ...
def upload_image_datalake(image_path): abeja_credential = { 'user_id': abeja_user_id, 'personal_access_token': abeja_personal_access_token } datalake_client = DatalakeClient(organization_id=abeja_organization_id, credential=abeja_credential) channel = datalake_client.get_channel(abeja_channel_id) res = channel.upload_file(image_path) datalake_file = channel.get_file(file_id=res.file_id) content = datalake_file.get_file_info() return content['download_url']
Datalake.download_urlの短縮化
LINE Botに通知する上で、LINE Messaging APIを利用する必要がありますが、Request Bodyに必要な originalContentUrl という参照可能な画像URLを指定するURLの制限として最大文字数があるため、bitlyを用いて短縮化を図っています。
def get_bitly_url(download_url): headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer {}'.format(bitly_auth_key) } body = { 'long_url': download_url } res = requests.post(bitly_post_url, json.dumps(body), headers=headers ) return 'https://{}'.format(res.json()['id'])
LINEへの通知結果
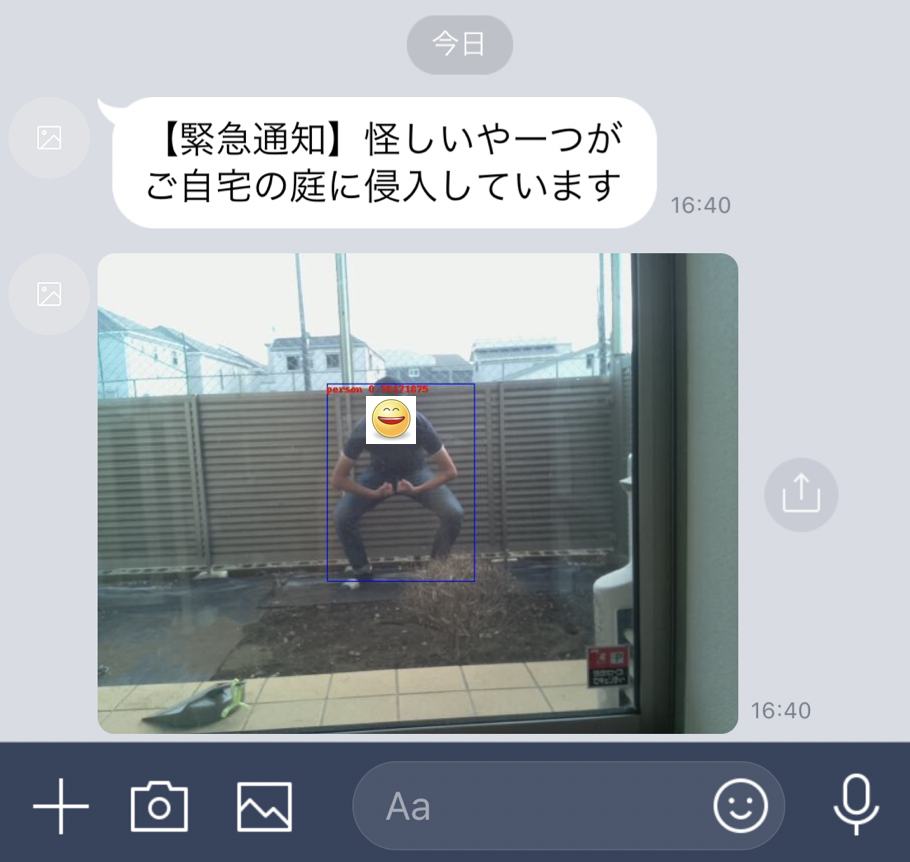
上のように人が検出された場合のみLINEにpush通知が来るようになりました。(注)smileのアイコンは自動的に付与されません。SSDで検出されたbounding boxも表示されてpush通知されています。侵入者が庭にいたという証拠も写真として押させることができた、また前回課題になっていた5秒間隔でCloudにある人物検出modelをAPIでcallすることなく、Edge側でその判定を持つことで見落とし無くリアルタイムに検知する仕組みを構築できました。次回は本当の住人を顔判定から見極め、そうではない不審者のみを通知することに挑戦したいと思います。
Raspberrypi zero WとABEJA Platformを活用した侵入者通知アプリを作る
やりたいこと
家庭で簡単に防犯カメラを作りたいと思い、下記のアイテムを利用して作ってみました。 僕の家はマンションの1階にあり、5〜6畳分の庭が付いています。庭内には植物・野菜を栽培したり洗濯物を干しているので、1階に住む住人としては不審者が入ってこないかどうかが気になったりします。そこで、Raspberrypi zero W, camera module, ABEJA Platform, LINE Messaging APIを用いて、不審者が庭内で検出された場合にLINEに通知が来る仕組みを作りたいと思います。LINEに通知するのは極力リアルタイムで検知したいというのと、写真で証拠を記録し通報に利用できるというメリットがあります。家庭のセキュリティサービスを展開しているものもありますが、初期工事費用や月額でそれなりにするので、もっと簡易な防災通知ができたらと思って試してみました。今回のRaspberrypi zero Wとcamera moduleだけだと5000円ほどで実現が可能です。
必要なもの
camera moduleの撮影条件と処理の流れ

家の中からRaspberrypi zero Wとcamera moduleで庭の写真撮影を行います。撮影された写真を下記の手順で記録し、もし人間が検出された場合にのみLINE Messaging APIにてLINEに通知します。
- 家の中から庭に向けてRaspberryapi zero Wとcamera moduleを設定
- camera moduleで撮影した画像をABEJA PlatformのWebAPIに定期的にupload。cronにより5秒間隔で撮影とWebAPIにuploadを実行。
- ABEJA PlatformのWebAPIにてSSDによる物体検出を行う
- 物体検出の結果、人間が判定された場合はその画像をLINE Messaging APIを利用してPush通知する
最近はRaspberrypi側で物体検出を行うことも試されていますが、ABEJA PlatformはAIのModelのアップデートが簡単なWebUIを用いてCloud側で実現できるので、Raspberrypi側はcameraの撮影処理とWebAPIのClientを一度書いてしまえば良いようにしておきます。ただし、外部との通信回数は当然増えます。
Raspi zero Wとcamera moduleを家の中から庭に向けて設置する

家の中から外に向けてcamera moduleと接続されたRaspi zero Wを設置します。庭に向けて侵入者をチェックする向きにします。上の写真は相当適当にRaspi zero Wを設置していますが、固定できるものがあると良いです。今回はRaspiを横にして、ウルトラマンフーマでRaspiを支えています。写真は前後から撮影した様子です。
Raspi zero Wの設定手順

Raspi zero Wにsshで接続する
黄色で囲った部分の設定を進めます。Raspi zero w, camera moduleを購入します。microsdのリーダーがあれば、OSの書き込みができるので、それを活用します。初期設定についてはここでは詳しく説明を記載しません。右記のドキュメントを参照してください。 Raspberry Pi Zero(W, WH)のセットアップ - Qiita Raspi側にsshで接続して、パッケージやOSのアップデートを行います。ちなみにRaspiのpythonはv2.7.13がdefaultだったので、pyenvを使ってv3.6.8に切り替えます。また必要なpython moduleのpicameraをinstallします。
$ ssh pi@raspberrypi.local $ sudo apt-get update $ sudo apt-get upgrade $ uname -a Linux raspberrypi 4.14.71+ #1145 Fri Sep 21 15:06:38 BST 2018 armv6l GNU/Linux $ python -V Python 2.7.13 $ sudo apt-get install -y git openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev $ mkdir .pyenv $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile $ pyenv install 3.6.8 $ pyenv global 3.6.8 $ python -V Python 3.6.8 $ pip install picamera
Raspi zeroのWifiの有効化
- Raspi zeroのWifiを有効化します。
- 有効なESSIDを抽出し、/etc/wpa_supplicant/wpa_supplicant.conf に設定を下記設定を記載
$ sudo iwlist wlan0 scan | grep ESSID
$ sudo vi /etc/wpa_supplicant/wpa_supplicant.conf
country=JP
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
network={
ssid="xxxxxxx" #抽出したSSID
psk="yyyyyy" #SSIDに紐づくパスワード
}
wconfigコマンドでwlan0が有効になっていることを確認します。
wlan0 IEEE 802.11 ESSID:"xxxxxx"
Mode:Managed Frequency:2.412 GHz Access Point: yyyyy
Bit Rate=52 Mb/s Tx-Power=31 dBm
Retry short limit:7 RTS thr:off Fragment thr:off
Power Management:on
Link Quality=37/70 Signal level=-73 dBm
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:1 Invalid misc:0 Missed beacon:0
camera moduleの有効化
Raspi側でraspi-configコマンドにて有効化。5 Interfacing Options Configure connections to peripherals を選択して、camera moduleをenableにします。vcgencmd get_cameraコマンドでsupported=1, detected=1となればcamera moduleの利用がOKな状態です。
$ sudo raspi-config 5 Interfacing Options Configure connections to peripherals P1 Camera Enable/Disable connection to the Raspberry Pi Camera [enable]を選択する $ vcgencmd get_camera supported=1 detected=1
テストコマンドで写真撮影をしてみる
raspistillコマンドで撮影と保存をしてみます。問題なくRaspi上で撮影・保存することができました。
$ raspistill -w 1280 -h 800 -o image.jpg $ ls -la image.jpg -rw-r--r-- 1 pi pi 651162 Aug 25 04:34 image.jpg
撮影処理の設定
以下のPython Scriptをcronなどに仕込んでおいて定期的に写真を撮影し、それをABEJA PlatformのAPIにrequestします。ABEJA PlatformのAPI側では受け取った画像をSSDの物体検出にかけます。ABEJA Platformは学習済みモデルを簡単にWebAPIとして作成することができるので、次章で作成したendpointを下記処理に加える必要があります。
import requests import picamera import time # endpoint付け足し url = 'https://abeja-internal.api.abeja.io/deployments/xxxxxxxx' user = 'user-xxxxxxxx' access_token = 'yyyyyy' headers = {'Content-Type': 'application/octet-stream'} with picamera.PiCamera() as camera: camera.resolution = (1280, 800) camera.rotation = 270 camera.start_preview() time.sleep(2) camera.capture('person_detect.jpeg') camera.stop_preview() files = {'upload_file' : open('./person_detect.jpeg', 'rb') } r = requests.post(url, files=files, auth=(user, access_token), headers=headers) print(r.content)
ABEJA Platformを使ったSSDによる人物検出

黄色で囲った部分の設定を進めます。 ABEJA Platformとは? ABEJAが開発するcloudを用いたAIの開発・運用基盤を意味します。詳しく知りたい方は以前にABEJA Platformに関するpostをしたので、そちらをご確認ください。ABEJA Platform上でSSDを使った物体検出・人物検出を行い、人物が検出された場合はLINE Messaging APIを使った通知をするという流れを作ります。SSDの物体検出モデルのソースコードと学習済みモデルは下記に存在します。
- https://github.com/rykov8/ssd_keras
- https://mega.nz/#F!7RowVLCL!q3cEVRK9jyOSB9el3SssIA
- weights_SSD300.hdf5
- weights_300x300_old.hdf5
ABEJA Platform上でSSDを動かす



ABEJA Platform上でjupyter notebookを操作することが可能なので、ssd_kerasや上で取得したweightファイルをuploadします。ssd_keras内にある SSD.ipynb というファイルをjupyter上で開けば実行することができます。このSSD.ipynbを拡張して、人を検出したときのみ次の処理に回すような設定をしました。サンプルは次のipynbになります。security-notification/SSD.ipynb at master · yutakikuchi/security-notification · GitHub
上で動作確認をし、SSD.ipynbの内容をABEJA Platform上のWebAPIとして実行するにはipynbの内容をモデルハンドラーとして実装、実行環境にモデルと実行ファイルをDeployする必要があります。Deploy後はABEJA PlatformのWebAPIのEndpointから画像ファイル取得、SSDのモデルに適用する事ができるようになります。モデルハンドラーの実装については下記に記載されています。
モデルハンドラー関数 for 19.04 :: ABEJA Platform Developers
LINEにpush通知を送る
Push通知先のChannel初期設定
LINEにpush通知を送るためには、https://developers.line.biz/console/ にてMessaging API用のchannel登録をする必要があります。 channel登録完了後に以下の情報をconsoleから抽出し、下記のAPIに対してrequestを送付するためのheaderやbody情報に加えます。
- Access Token :
アクセストークン(ロングターム)と記載されている項目 - To(送付先) :
Your user ID
またchannelの基本情報画面にBotのQRコードが掲載されるので、必ず友達として追加する必要があります。Push通知のメッセージは追加されたBot側のアカウントにメッセージと画像が表示されます。
LINE Messaging APIにRequestする

黄色で囲った部分の設定を進めます。 LINE Messaging APIを利用してLINEに対してPush通知をします。LINEへのMessaging pushを行うにはbinaryのpostではなく、画像をURLを必要とします。よってABEJA Platform Datalakeに人物検出をされた場合は画像をアップロードし、画像のURLを発行し、そのURLを基にLINEのAPIに対してpushします。ここではABEJA PlatformのDatalakeについては特に記載をしません。
- Endpoint :
https://api.line.me/v2/bot/message/push - Content-Type :
application/json - Authorization :
Bearer <Access Token> - Request Body : JSON format
下記にLINEへのpush通知のサンプルコードを記載します。このサンプルコードをABEJA PlatformのWebAPIのロジックの中に加えます。
import requests import json headers = { "Content-Type": "application/json", "Authorization": "Bearer <Access Token>" } body = { "to" : "xxxxxxx", "messages":[ { "text": "【緊急通知】怪しいやーつがご自宅の庭に侵入しています", "type": "text" }, { "type": "image", "originalContentUrl" : "https://xxxxxxx", "previewImageUrl" : "https://xxxxxxx" } ] } response = requests.post( 'https://api.line.me/v2/bot/message/push', json.dumps(body), headers=headers )
LINEへのpush通知の結果
人が検出された場合のみLINEにpush通知が来るようになりました。(注)smileのアイコンは自動的に付与されません。SSDで検出されたbounding boxも表示されてpush通知されています。侵入者が庭にいたという証拠も写真として押させることができたので、これで目的が達成です。ただし、夜など暗い撮像条件下ではほとんど反応しない、本当の住人を顔判定で通知の除外対象としたかったのですが、現時点での課題は多くあります。

ラーメン二郎分類器 : ABEJA Platformを使ってサービス公開するぞ
ラーメン二郎分類器

引用 : ラーメン二郎 三田本店 (らーめんじろう) - 三田/ラーメン | 食べログ
皆さん、ラーメン二郎は好きですか? 好きですよね? 僕は大学の目の前にラーメン二郎があったので足繁く通っていました。しかし、ラーメン二郎初心者にとっては、麺の画像を見て、それが「ラーメン二郎」なのか「長崎ちゃんぽん」なのかが見分けが付きづらいと思います。よってDeepLearningを用いて、それらの分類を自動化する仕組みをABEJA Platformを使って実装する方法について記載します。データのcrawlingなどの実装は必要ですが、学習に関してはtemplateという機能を利用するとノンプログラミングでもモデル作成が可能なので、以下の作業時間はおおよそ10分で完了できます。
既にABEJA Platform、ABEJA Platform Annotationについては記事にしているので、以下のリンクも参考にしてください。
必要なもの
- python
- version 3.6.6 (versionはこれに限定されず、実行可能)
- 「ラーメン二郎」と「長崎ちゃんぽん」の麺が写っている写真、学習データ
- icrawlerを利用してABEJA PlatformのDatalakeに結果を格納
- ABEJA Platform
- ABEJA Platformのアカウントを必要とします。
- ご利用されたい方は下記の問い合わせよりお願いいたします。
- https://abejainc.com/platform/ja/contact/
- ABEJA Platform SDK
- ラーメン二郎への愛情
- 愛情があると良し。ただし、必須ではない
手順
- ABEJA Platformのjupyter notebookを利用する
- icrawlerで画像を保存する
- 学習データのメタ情報をjsonとして作成
- ABEJA Platform Datalakeへchannelを作成
- ABEJA Platform Datalakeへ画像を登録
- ABEJA Platform Datasetの作成、学習データをimportする
- ABEJA PlatformのTemplateを用いて学習、Deployする
手順の図解
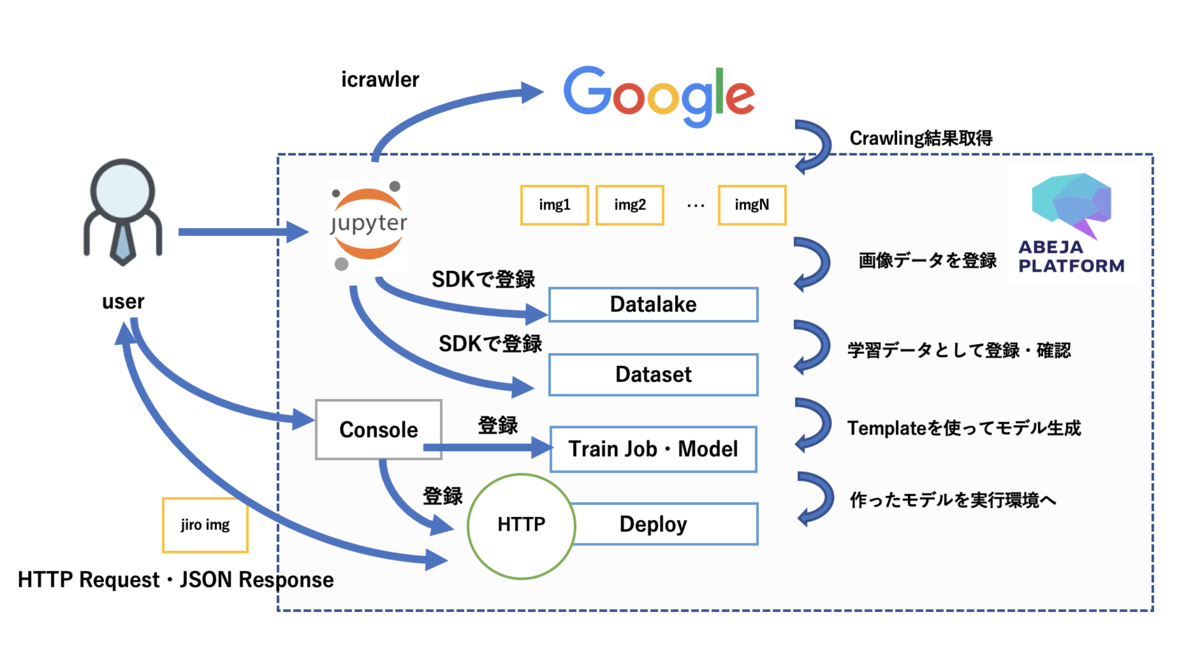
ラーメン二郎分類器をつくる
ABEJA Platformのjupyter notebookを利用する
ABEJA PlatformはCloud上でMLOpsのプロセスを実行することが可能、いわゆる機械学習の開発・運用基盤です。ABEJA Platformのアカウントを持っていれば、Consoleという管理画面が使え、その上でjupyter notebookで作業を進めることができます。 https://console.abeja.io アカウントがある方はこちらからログイン後にjupyter notebookを使うことができます。アカウントが無い方は https://abejainc.com/platform/ja/contact/ から問い合わせをお願いいたします。
上の図はABEJA Platform上でjupyter notebookを扱っている例です。尚、以下では各種実行に必要な変数がありますが、Consoleから全て確認ができますので、確認した値をご利用ください。
- organization_id = 'xxxxxxxxx' - user_id = 'user-xxxxxxxxx' - personal_access_token = 'xxxxxxxxx' - channel_id = 'xxxxxxxxx'
icrawlerで画像を保存
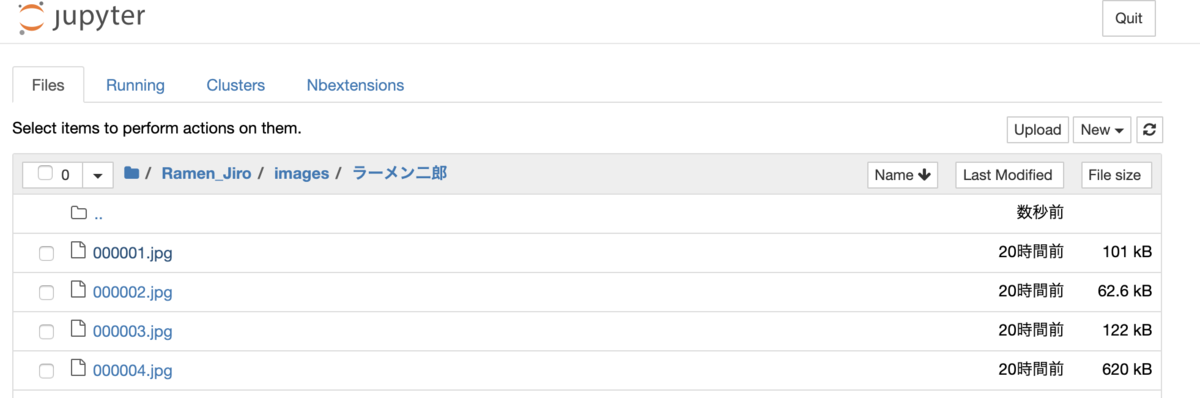
from icrawler.builtin import GoogleImageCrawler # getting crawling data using icralwer # search query queries = [u'ラーメン二郎', u'長崎ちゃんぽん'] for q in queries: print(q) crawler = GoogleImageCrawler(storage = {'root_dir' : 'images/'+q}) crawler.crawl(keyword = q, max_num = 200)
今回はicrawlerを利用してGoogleの検索結果からラーメン二郎と長崎ちゃんぽんの画像を引っ張ってきます。まずはABEJA Platformでのnotebookの作業配下に images/{query} というディレクトリを切って画像を保存します。それぞれ200枚ずつのデータを蓄積します。sample codeは上記のものになります。sample codeを実行すると上図のようにjupyter notebookの作業ディレクトリ配下に画像が保存されます。
学習データのメタ情報をjsonとして作成
import json # create training categories data json_data['categories'] = {} category_data = [] category_data.append({'labels':[], 'category_id':1, 'name':'Ramen'}) labeled_data = [] labeled_data.append({'label_id':1, 'label':'Ramen_jiro'}) labeled_data.append({'label_id':2, 'label':'Nagasaki_Champon'}) labeled_data.append({'label_id':3, 'label':'Other'}) json_data['categories'] = category_data json_data['categories'][0]['labels'] = labeled_data # format is below # {"categories": [{"labels": [{"label_id": 1, "label": "Ramen_jiro"}, {"label_id": 2, "label": "Nagasaki_Champon"}, {"label_id": 3, "label": "Other"}], "category_id": 1, "name": "Ramen"}]} json.dump(json_data, open('categories.json','w'))
学習データを作成するために、icrawlerによって集めた画像が何のラベルを持つべきかの定義を行います。定義としてはlabel_id : 1〜3、それぞれにRamen_jiro、Nagasaki_Champon、Otherという形でラベル名を持ちます。このあとの作業としてABEJA Platform Datalakeに画像を登録しつつ、その画像が何のLabelなのかを一緒に登録します。これでcrawlingした結果をそのまま学習データとして活用する事ができます。もちろん、Datalakeに登録した画像をAnnotationして人の目を通して学習データを手作業で作成することもできます。ただし、ここでは省略。
ABEJA Platform Datalakeへchannelを作成
A Sample tutorial — ABEJA Dataset Library documentation
from abeja.datalake import Client as DatalakeClient from abeja.datalake.storage_type import StorageType # create ABEJA Platform Datalake channel organization_id = 'xxxxxxxxx' user_id = 'user-xxxxxxxxx' personal_access_token = 'xxxxxxxxx' credential = { 'user_id': user_id, 'personal_access_token': personal_access_token } datalake_client = DatalakeClient(organization_id=organization_id, credential=credential) name = 'Ramen_jiro' description = 'a channel for ramen_jiro' channel = datalake_client.channels.create(name, description, StorageType.DATALAKE.value)
収集したラーメン二郎と長崎ちゃんぽんの画像データをABEJA Platform DatalakeというObject Storageに保存します。。まずDatalakeに対しての手順として、1.channelを作成する、2.channelにデータを登録する が必要になります。Datalakeへの操作としてはABEJA Platform SDKがあるので、それを利用すると簡単なpythonコードで操作が可能になります。SDKのドキュメント、チュートリアルは上のURLにあります。上のsample codeを実行するとDatalakeにchannelを作成します。channelはデータソースを定義するために作成します。今回で言うラーメンの画像とラベルデータの保存先となります。
ABEJA Platform Datalakeへ画像を登録
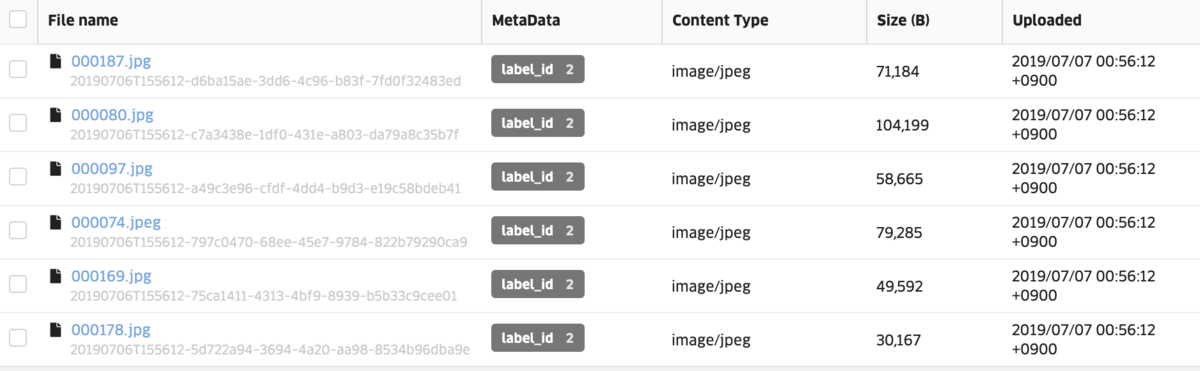
import glob from abeja.datalake import Client as DatalakeClient # upload images client = DatalakeClient() organization_id = 'xxxxxxxxx' channel_id = 'xxxxxxxxx' datalake_client = DatalakeClient(organization_id=organization_id) channel = datalake_client.get_channel(channel_id) queries = [{'name':u'ラーメン二郎', 'label_id':1},{'name':u'長崎ちゃんぽん','label_id':2}] for q in queries: files = glob.glob('images/'+q['name']+'/*') metadata = {'label_id':q['label_id']} for file in files: res = channel.upload_file(file, metadata=metadata)
jupyter notebook上でicrawlerがimages/{query}という形で保存先のディレクトリでデータを切り分けたので、それぞれの画像データと正解データとなるlabel_idをDatalakeに登録します。sample codeは上記のものになります。sample codeを実行すると上図のようにDatalakeのchannelに画像データとlabel_idのデータが閲覧可能になります。
ABEJA Platform Datasetの作成、学習データをimportする
import json from abeja.datasets import Client # create dataset ORGANIZATION_ID = 'xxxxxxxxx' client = Client(organization_id=ORGANIZATION_ID) props = json.load(open('categories.json','r')) dataset = client.datasets.create(name='ramen_jiro_dataset', type='classification', props=props)
Datalakeに登録したデータを学習データとして扱う、目視で確認するためにDatasetという機能を利用します。まずはdatasetを作成します。学習データのメタ情報をjsonとして作成 のパートで保存したcategories.jsonというファイルをここで利用します。
from abeja.datalake import Client as DatalakeClient # get datalake files # import from datalake to dataset client = DatalakeClient() organization_id = 'xxxxxxxxx' channel_id = 'xxxxxxxxx' datalake_client = DatalakeClient(organization_id=organization_id) channel = datalake_client.get_channel(channel_id) for file in channel.list_files(): source_data = [ { 'data_type': file.content_type, 'data_uri': file.uri, } ] attributes = { 'classification': [ { 'category_id': 1, 'label_id': file.metadata['label_id'] } ] } dataset_item = dataset.dataset_items.create(source_data=source_data, attributes=attributes)
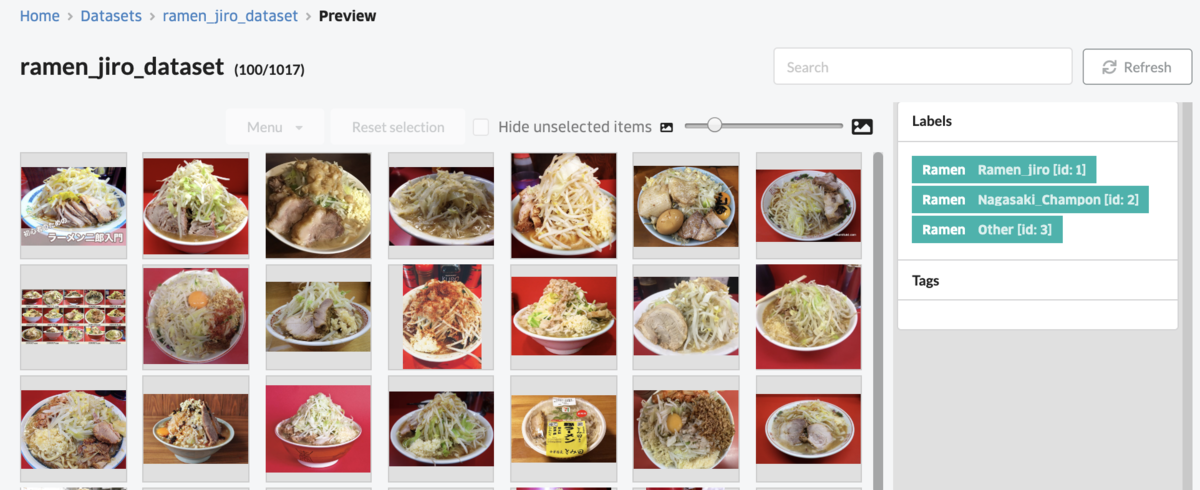
次にDatalakeからDatasetに対象のデータをimportします。上記sample codeを実行するとDatasetの画面から一覧を確認することができます。画面右にあるlabelをクリックするとラーメン二郎、長崎ちゃんぽんのそれぞれのDatasetを見ることができます。
ABEJA PlatformのTemplateを用いて学習、Deployする
Templateの中身については上記githubに詳細が記載されています。 This template uses transfer-learning from VGG16 ImageNet. モデルはVGG16の転移学習によって行われています。
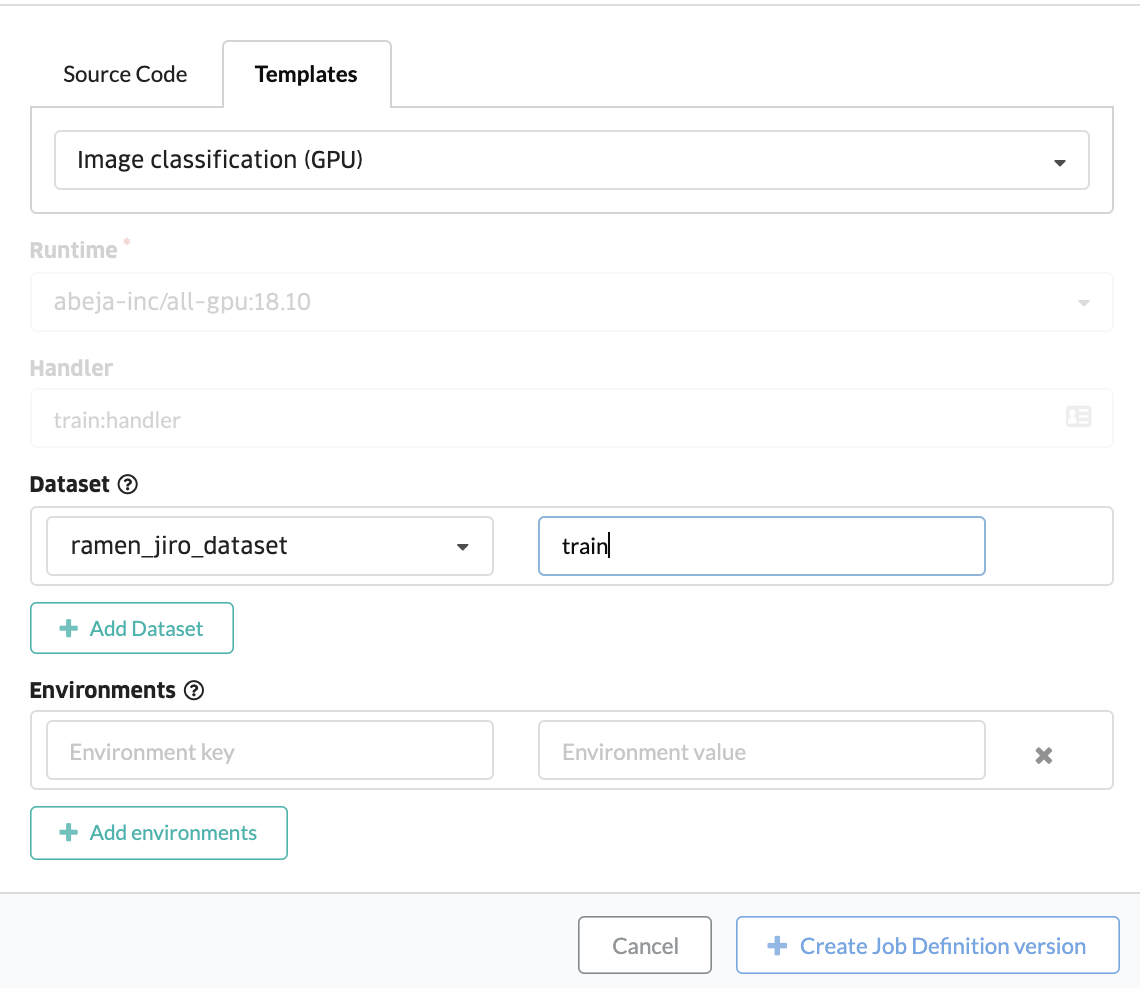
ABEJA PlatformのConsoleを使って、学習のTemplateを利用します。ConsoleのJob Definitionというメニューから学習jobを設定できます。Template機能を使う場合は、表示された画面の中で Templates というタブを選択してください。ソースコードを登録したい場合は Source Code というメニューを選択しますが、今回はSource Codeは使用しません。


続けてtrain jobを作成します。先程登録したTemplateのjobをこちらの画面で登録していきます。上記画面にて項目を選択するだけで実行が可能です。しばらくするとtrain jobが停止し、学習が完了した状態を確認することができます。

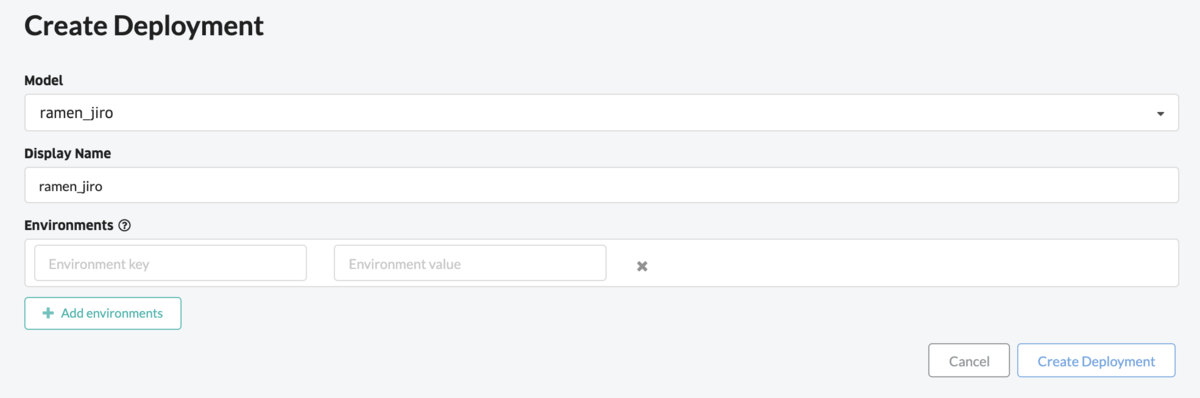
Train jobと同様にDeployについてもノンプログラミングで行います。Deployの機能は作成したモデルを実行できる環境に配置することです。ここではWebAPIとして実行する例を記載していきます。上図ではまずはTrain jobで作成されたモデルを定義しています。作成されたモデルをDeployするための設定も付け加えます。これでモデルを実行できる環境が整いました。
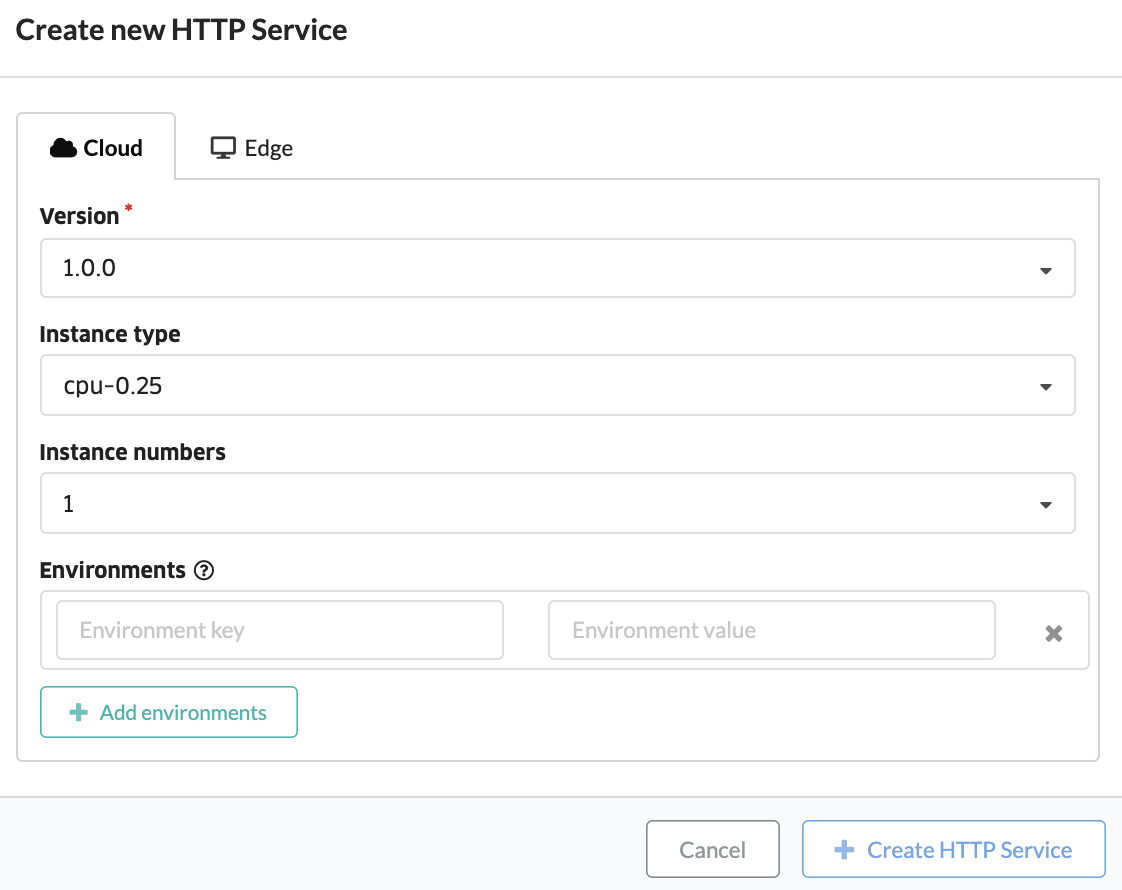
DeployされたモデルをWebAPIとして呼び出すための設定を加えます。Deployの画面で 必要な項目を選択、Create HTTP Service ボタンを押下します。
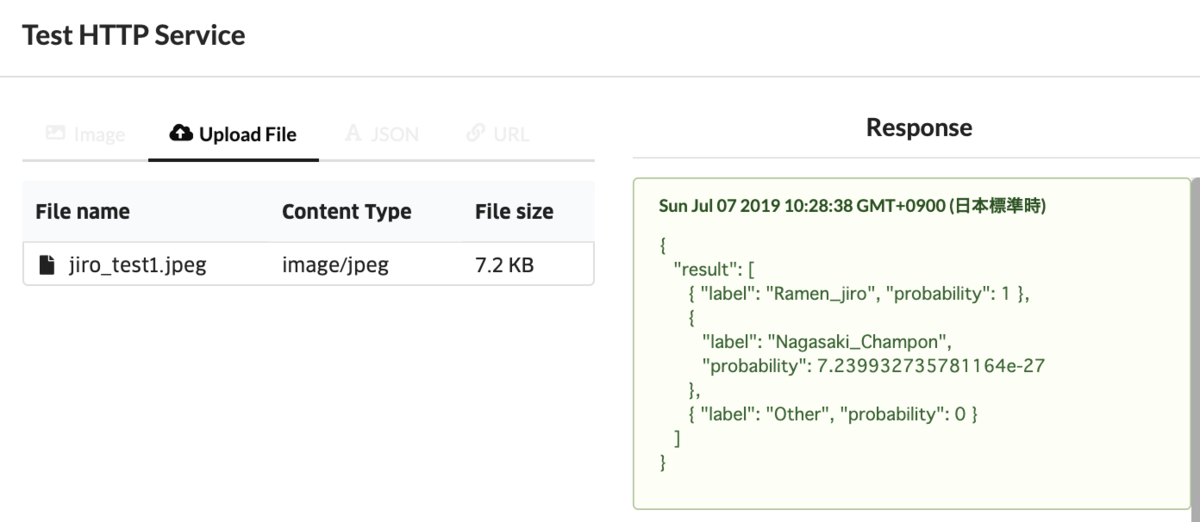
{ "result": [ { "label": "Ramen_jiro", "probability": 1 }, { "label": "Nagasaki_Champon", "probability": 7.239932735781164e-27 }, { "label": "Other", "probability": 0 } ] }
作成されたHTTP Serviceに対してテストを実施してみます。ラーメン二郎の画像をアップロードし、それに対してJSONフォーマットでの結果が返ってくることを確認します。上記のようにRamen_jiroであるProbabilityが1となっているので、100%ラーメン二郎だという回答になっています。あとはHTTP Serviceを外部向けのサービスとして公開するだけです。Deployの画面でAdd Endpoint というボタンを押下すると外部向けのEndpointが作成されるので、作成されたEndpointに対して画像をpostすると上記テストと同じようにJSONフォーマットの結果が返ってきます。
cURL command curl -X POST \ -u user-xxxxxxxxx \ -H "Content-Type: image/jpeg" \ --data-binary @jiro_test1.jpg \ https://abeja-internal.api.abeja.io/deployments/yyyyyyyy
{ "result": [ { "label": "Ramen_jiro", "probability": 1 }, { "label": "Nagasaki_Champon", "probability": 7.239932735781164e-27 }, { "label": "Other", "probability": 0 } ] }
最後に
いかがでしたでしょうか。ABEJA Platform上でjupyter notebook、consoleを使いこなし、更にはモデルのアルゴリズムの中身を知らなくてもノンプログラミングでサービス化までできます。本日の内容は本当に簡単なものを紹介しましたが、これらの機能を利用することで様々なサービスをABEJA Platform上で公開することができます。その他、多くのドキュメントがあるので、是非下記URLを参照してください。