学習データの蓄積を加速する ABEJA Platform Annotation

ABEJA Platformについて
前回のPostでABEJAが開発しているMLOpsの課題を解決するABEJA Platformの概要について説明しました。このPostではABEJA Platformの一機能であり、学習データの蓄積を加速する ABEJA Platform Annotation について紹介します。
ABEJA Platform Annotationとは
今回はMLOpsで重要な学習データを蓄積するためのAnnotationについて書きます。そもそも学習データとは?という方もいると思うので、簡単に一言で表すと、人工知能のモデルを作るための知識・入力データと言えます。人間も学習という訓練を重ねながら脳を賢くする、このプロセスは人工知能も同じで、正しい知識から学ばなければならない。Annotationとは人工知能にとって正しい知識となるデータを作成するプロセスを示します。
よってAnnotationは非常に重要なプロセスです。なぜならば人工知能が正しい知識を得なかった場合、正しい反応をすることができません。人間も同様ですね。仮に教科書が間違っていたらそこから学んだ人も誤った知識を得て、テストで間違えてしまう。こういった事が発生しないよう、ABEJAはPlatformの一機能としてAnnotationを仕組みとして提供しています。(学習データを人工知能によって全てを自動生成することもできますが、ここでは学習データの作成は人が行うことを想定した書き方をしています。なぜならば人工知能による自動生成は誤ってしまう可能性があるためです。)

引用 : 概要 Annotationは上記AI Development Pipeline(AIに必要な開発・運用プロセスという定義)の4番目に位置するプロセスになります。
Annotation作業の具体例
学習データ作成の具体例を見てみましょう。例えば、犬と猫の画像を人工知能を使って分類したいとう問題を解くことを想定します。人は既に持っている知識から画像を見たときにそこに犬か猫が写っているかを瞬時に判別することが可能です。学習データの蓄積とは人間の知識を基に、画像の1枚ずつを目視で確認し、画像に対して犬か猫かのラベル付をしていきます。よって学習データとは下記のようと言えます。
学習データ = そもそものデータ(画像だけ) + ラベルデータ(犬か猫のラベル)


犬か猫かの判別は非常に簡単な問題です。複雑になるAnnotationとしては、犬の中でも更に犬種を分類したいとなると、多くある犬種のラベルを人間が確認しながらラベルを付与する形になります。人間が正しくこれらを判別するにはある程度の学習期間が必要だったりします。人工知能に必要な学習データ作成のために、人間が正しい知識を学習する、なんだが複雑な話です。
また上にABEJA Platform AnnotationのUIを使った作業内容の動画があります。Annotationの作業者がこのUIを使いながら作業を進めます。上では犬と猫の話をしましたが、動画中のObject Detectionのように一枚の画像の中で複数の物体を検出するための学習データを作成することもできます。
ABEJA Platform Annotationの価値は
 引用 : ABEJA Platform Annotation
引用 : ABEJA Platform Annotation
Annotationの作業において重要なポイントは下記のものになります。
- 大量のデータ作成を多数の作業者で分担し、学習データの蓄積をスムーズに行うこと
- 誤った学習データではなく、品質の高い学習データを作成をすること
- 作られた学習データが後段の学習プロセスにすぐ活用できること
ABEJA Platform Annotationは上記内容の全てをツール機能として提供しています。
1. 大量のデータ作成を多数の作業者で分担し、学習データの蓄積をスムーズに行うこと
ABEJAは多くのBPO(Business Process Outsourcing)会社と連携し、社内・外のAnnotation作業を実施する担当者を供給することができます。総勢10万人の作業者に作業を依頼することが可能なので、例えば10万枚の画像に対して何が写っているかをAnnotationするという作業についても、タスクを分散させれば作業自体は短い時間で完了を目指すことができます。
これまではData Scientistが限られた時間の中で黙々と作業を重ねられているという話も聞いたことがありますが、これからはABEJA Platform Annotationを使えば直ぐに解決する問題であり、Data Scientistは本来価値を発揮すべき作業ポイント、特に機械学習のモデル開発・チューニングに集中する事ができます。
2. 誤った学習データではなく、品質の高い学習データを作成すること
上で作成した作業に関して、BPO会社内・ABEJA社内の作業マネージャーがAnnotation作業の状況を確認することができます。全てのAnnotation作業のデータを確認することが難しい場合もあるので、そういったときはサンプリングしながらの確認になります。各作業者ごとに成果物の品質のチェックを行い、例えば品質が良くなければ次回以降の作業のためにその担当者を教育を実施するといった対応が可能になります。また最初から全てのタスクをAnnotationの作業者におまかせするのではなく、最初はトライアルタスクとして少ない数の作業を各作業者に依頼、問題ないことを確認した上で本番のタスクをアサインするというのも運用として行うことができます。
その他の方法として、難易度が高いAnnotation作業の場合は、複数人で同一データに対する作業を行い、多数決方式で正解ラベルを決定するという手段もあります。繰り返しになりますが、マネジメントの工数を掛けてでも、品質の高いデータを作成すること、人工知能に対して正しい知識をインプットすることが重要になります。
3. 作られた学習データが後段の学習プロセスにすぐ活用できること
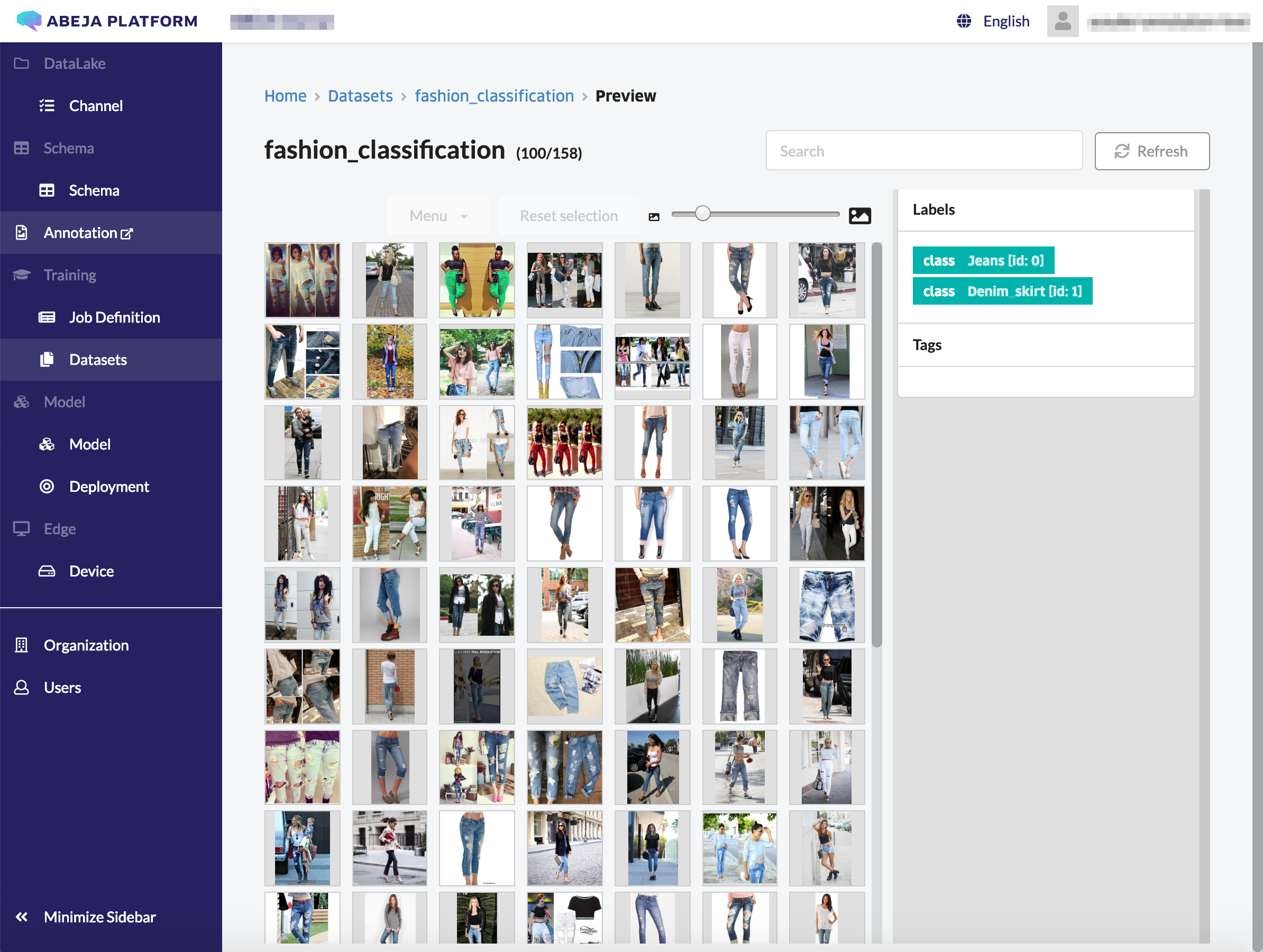
引用 : アノテーションツールの利用
上の図はFashionのitem画像が何の種類であるかを判別するためのモデルを作りたいときにAnnotationされた結果をABEJA PlatformのGUIから閲覧している状況です。付与されたラベル(例としては、JeansやDenim Skirt)でフィルタし、該当するものだけを抽出してAnnotationの結果を閲覧することもできます。
ABEJA Platformには学習データを基にした学習処理をCloud上で実行する環境を保有しています。学習データ量が大きく、または複雑なアルゴリズムを適用する場合、非常に多くの計算リソースを必要とする場合があります。ABEJA Platform Annotationで蓄積されたデータはABEJA Platformの学習基盤と直ぐに連携し、学習プロセスを実行する事ができます。 ここがまさにOnestopなServiveを展開している価値であり、ABEJA PlatformのGUIから簡単な操作で全てのMLOpsに関わる全てのプロセスの実現が可能です。
その他
本日はABEJA Platform Annotationについて説明しました。ABEJA Platform Annotationのwebサイト、ABEJA Platformの利用者向けサイト、QiitaにもABEJA PlatformおよびAnnotationの内容が記載されているので、是非下記のリンクを御覧ください。
MLOpsの課題を解くABEJA Platform
はじめに
私は日本のAI Startupの 株式会社ABEJA という会社に所属しています。ABEJAの中では主に製品開発・事業開発を携わっています。所属している人間が言うのもアレですが、ABEJAの製品、その裏側で使われている技術は state-of-the-art なものであり、それを作っている・売っている両方のメンバーが非常に優秀です。
今日は簡単にABEJA Platformの紹介をしていきたいと思います。このPostをきっかけとして何度かABEJA Platformに関する記事を投稿する予定なので、機械学習をビジネスに実装する上でのMLOpsに課題を持っている方はそれを解決するための手段として是非ABEJA Platformをご利用いただきたいと思います。
ABEJA Platformとは
それでは本題に入ります。ABEJA Platformとは何か? ABEJA Platformの機能を簡単に表現すると表題の通りMLOpsの課題を解くAwesomeな製品になっています。(機能以外にも機械学習ビジネスを展開するためのPlatformでもありますが、それは後日紹介します。) 現在におけるData Scientistの方々の業務領域の定義が広く・曖昧な状況が続き、MLOpsに関わる多くの作業を彼ら自身が実施しなければならないケースがあります。しかし、これは本当に正しい状態と言えるでしょうか。Data Scientistに一番求めるスキルを機械学習モデルの開発・チューニングと定義された場合、機械学習のモデルをDeliveryするためのシステム運用のインフラを構築することを依頼するのは守備範囲を広げてしまい、本来求めたかったミッションから遠ざかります。
機械学習のモデル開発・運用に必要とされる人間が関わるプロセス(ABEJAが言うAI Development Pipeline)を最小のコストで実現すること、Data Scientistのコアコンピタンスを明確に定義し、開発・チューニングに専念してもらうこと、その結果いち早くビジネスに対して機械学習の導入を進めること、このような目的でABEJA Platformの開発が行われています。ABEJA PlatformはOnestopな製品であり、非常にシンプルです。多くのサービスを組み合わせてAI Development Pipelineの実行をする必要がないので、全ての操作を一つの管理画面から実行することが可能です。

引用 : https://abejainc.com/platform/
ABEJA Platformとの連携
ABEJA PlatformはCloudをベースとした機械学習の開発・運用基盤と言えます。最近においてはCloudとお客様のOn-premisesを連携するための開発も進めており、今後多くの皆さんにご利用いただくための最適な環境を提供したいと考えています。On-premisesな環境の一つとして、CloudとIoTデバイス(Edge)との連携が可能なようにしています。例えば、データの取得元・機械学習モデルの実行環境としてはIoTデバイスで行い、学習データの蓄積・モデルの生成はCloudで行うという、使い分けをすることもできます。
今後あらゆる場面でIoTデバイスの導入が進むことは明らかなので、ABEJAとしてもEdgeとの連携については多くのビジネス機会があると考えています。( 下記図に記されているように、上りのIoT、下りのIoTの連携が進む。上りのIoTとはデバイスからクラウドにデータを預ける、下りのIoTで預けたデータから生成された新しい価値をデバイス側に届けるという意味合い)

引用 : https://abejainc.com/platform/
最後に
いかがでしたでしょうか。機械学習のモデル開発をやられたことがある方は、MLOpsの経験者は共感いただけるポイントが多かったと思います。現在はABEJA Platformの公式ドキュメントを一般公開しているので、是非ご覧頂きたいと思います。
またQiitaにも情報を公開していますので、より実活用のイメージを持っていただければと思います。今日のpostは第一回目なので、今後複数回に渡ってABEJA Platformを紹介していきます。繰り返しになりますが、興味を持たれた方は是非問い合わせフォームから依頼を投げていただければと思います。https://abejainc.com/platform/ja/contact/ こちらからお願いいたします。
暗号通貨の価格推移データをGoogle Spreadsheetを使ってHackする
やること
- Google Spreadsheetだけで暗号通貨の価格推移データを取得する
- 取得したデータを基にデータの可視化、分析を行う。※ 今回のentryではその準備までを対象とする
Ref
- Google Spreadsheetに暗号通貨の価格推移データを表示するrepositoryを下記に設置
- GitHub - yutakikuchi/crypto-currency-googlespreadsheet
Hack方法① : GoogleFinance関数
- Google Spreadsheetのデフォルト関数である
GoogleFinanceを利用する- 関数例 :
=GoogleFinance("CURRENCY:BTCJPY" , "price", TODAY()-10,TODAY(), "DAILY") - ただし、この方法ではBTCしか出力ができない
- 関数例 :
Hack方法② : IMPORTXML関数
- Google Spreadsheetのデフォルト関数である
IMPORTXMLを利用して、https://coinmarketcap.com/ja/currencies/ からデータを取得する- 今回のHack方法。Google Spreadsheetだけでcoinmarketcapからデータをスクレイプする
- またGoogleFinance関数を利用してUSD to JPYも計算している

- 下記にSampleのGoogle Spreadsheetを掲載。end_dateから10日間遡ってデータを取得する
- coinmarketcapで扱っている通貨であれば対応は可能
- Crypto Currency Historical - Google スプレッドシート
- ※ ただし、この方法はimportに時間が掛かる
Hack方法③ : AddonのCRYPTOFINANCEを利用
- Google Spreadsheetのaddonである
CRYPTOFINANCEを利用する

導入手順 : Hack方法② IMPORTXML(crypto-currency-googlespreadsheet)
- crypto-currency-googlespreadsheet/README.md at master · yutakikuchi/crypto-currency-googlespreadsheet · GitHub
- Google Spreadsheetを1つ用意し、sheetタブを2つ作成する
- 1つは値動きを表示するsheetタブ、もう一つは各種パラメータを設定するもの
- sheetタブの名前はそれぞれ下記のものとする
Parameter SheetCrypto Currency
- Parameter Sheetの内容は下記スクリプトを実行、Sheetに貼り付ける
python parameter_sheet.py
- Crypto Currencyの内容は下記スクリプトを実行し、Sheetに貼り付ける
python currency_table_gen.py 100
Hack方法②のGoogle Spreadsheetのサンプル
Hugo + Github PagesでMarkdownで書いた記事を公開する
Ref
Goal
- Hugoで作った静的ページをGithub Pagesで公開することを目標とする
- About GitHub Pages - GitHub Docs
- Github Pagesには2種類ある
- Projectで設定する :
https://(USERNAME).github.io/<Project> - User, Organizationで設定する :
https://(USERNAME).github.io/
- Projectで設定する :
- 今回は前者(Projectで設定する)の方法で実施する
- Hatena Blogで公開していたpostをMovable Type形式でExportして、Github Pages上にMarkdown形式で設置
- Hatena Blog : Y's note
- Export : 記事データをエクスポートできるようにしました。ブログのバックアップ等にご利用ください - はてなブログ開発ブログ
Hugo, Github Pages
MacへHugoをinstall
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.4 BuildVersion: 18E226 $ brew install hugo $ hugo version hugo version Hugo Static Site Generator v0.55.4/extended darwin/amd64 BuildDate: unknown
Movable Type型をHugoの形式(Markdown型)に変換
- Hatena Blogのpostをexportしたい
- Hatena BlogのExport機能はMovable Type型でしかできない。よってHugo形式のMarkdownに合わせる必要がある
- 以下にsampleコードがあるので、Movable Type形式から変換するように改修する
- 改修したファイルは次の名前で定義。hatena_2_hugo.rb
$ rbenv exec bundle exec ruby hatena_2_hugo.rb hatena_export.txt md_output
- md_outputのディレクトリに各post毎に
YYYYmmddHHMM.mdとして出力される
$ head -n 10 md_output/_posts/201904292103.md --- title: "Docker for Macのメモリ制限の調整" date: 2019-04-29T21:03:52+00:00 category : [etc] canonicalurl: http://yut.hatenablog.com/entry/2019/04/29/210352 --- ## [etc] : Docker for Macのメモリ制限の調整
- 元のHatena Blogの検索インデックスに悪影響を及ぼさないようにMovable Typeで出力されたBASENAMEからcanonicalurlを設定している
- canonicalurlのパラメータをHugoのtemplateからparameterとして読み込むことができる
Gitの設定、Hugoのファイル構成設定
- Github Pagesでprojectの静的ページを公開する方法は3つ紹介されている
- 公開用の静的ページをmasterのdocsディレクトリ配下に置く
- 公開用の静的ページをgh-branchの直下に置く
- 公開用静的ページをmasterの直下に置く
- 今回は1.の方法で実施。
- Hugoのtemplateを作成する。ディレクトリの名前は
blog - github上に適当な名前のrepositoryを作成する
- 今回はディレクトリ名に合わせて
blogという名前で作成 - Postのソースを管理するbranchを
gh-pagesとして作成
- 今回はディレクトリ名に合わせて
- Hugoのthemeである
blackburnを利用する
$ hugo new blog $ git init blog $ cd blog $ git add --all $ git commit -m "first commit" $ git remote add origin git@github.com:yutakikuchi/blog.git $ git push -u origin master $ git checkout -b gh-pages $ cd themes $ git clone https://github.com/yoshiharuyamashita/blackburn.git $ cd ../ $ mkdir -p content/post
- hugoディレクトリの下にできる
config.tomlとcontentに対して手を加えていく。blackburnのthemeのconfig.tomlを以下のように設定
$ cat config.toml | pbcopy baseurl = "https://yutakikuchi.github.io/blog/" # Make sure to end baseurl with a '/' languageCode = "ja-jp" title = "Y's note" author = "菊池佑太" # Shown in the side menu copyright = "© 2019. All rights reserved." canonifyurls = true paginate = 10 publishDir="docs" [indexes] tag = "startup,AI" topic = "スタートアップ,AIに関わる内容を書きます" [params] # Shown in the home page brand = "Y's note" googleAnalytics = "UA-20616165-3" # CSS name for highlight.js highlightjs = "androidstudio" highlightjs_extra_languages = ["yaml"] # dateFormat = "02 Jan 2006, 15:04" dateFormat = "2006 Jan 02, 15:04" # Include any custom CSS and/or JS files # (relative to /static folder) custom_css = ["css/my.css"] custom_js = ["js/my.js"] # canonicalurl canonicalurl = "http://yut.hatenablog.com" #[params.piwikAnalytics] # siteid = 2 # piwikroot = "//analytics.example.com/" [menu] # Shown in the side menu. [[menu.main]] name = "Home" pre = "<i class='fa fa-home fa-fw'></i>" weight = 1 identifier = "home" url = "/" [[menu.main]] name = "Posts" pre = "<i class='fa fa-list fa-fw'></i>" weight = 2 identifier = "post" url = "/post/" [[menu.main]] name = "About" pre = "<i class='fa fa-user fa-fw'></i>" weight = 3 identifier = "about" url = "/about/" #[[menu.main]] # name = "Contact" # pre = "<i class='fa fa-phone fa-fw'></i>" # weight = 4 # url = "/contact/" [social] # Link your social networking accounts to the side menu # by entering your username or ID. # SNS microblogging twitter = "yutakikuchi_" # gnusocial = "*" # Specify href (e.g. https://quitter.se/yourusername) facebook = "yuta.kikuchi.007" # googleplus = "*" # weibo = "*" # tumblr = "*" # SNS photo/video sharing # Instagram = "*" # Flickr = "*" # Photo500px = "*" # Pinterest = "*" # Youtube = "*" # Vimeo = "*" # Vine = "*" slideshare = "https://www.slideshare.net/yutakikuchi58/" # SNS career oriented linkedin = "https://www.linkedin.com/in/%E4%BD%91%E5%A4%AA-%E8%8F%8A%E6%B1%A0-36291a44/" # xing = "*" # SNS news # reddit = "*" # hackernews = "*" # Techie github = "yutakikuchi" # gitlab = "*" # bitbucket = "*" # stackoverflow = "*" # serverfault = "*" # Gaming # steam = "*" # mobygames = "*" # Music # lastfm = "*" # discogs = "*" # Other # keybase = "*"
- またcontent/postのディレクトリに対して
hatena_2_hugo.rbで生成されたmdファイルを設置 themes/blackburn/layouts/partials/head.htmlをcanonicalurl変数を読み込めるようにheaderを修正- hugoのserverを起動し、ページが閲覧できるか確認
- http://localhost:1313/ を見てみるとページを確認することができる
$ cp ~/md_output/* content/post/ $ ls -la content/post | head -n 5 total 9624 drwxr-xr-x 208 yuta staff 6656 5 2 11:36 ./ drwxr-xr-x 3 yuta staff 96 5 2 11:36 ../ -rw-r--r-- 1 yuta staff 1926 5 2 11:37 201009060134.md -rw-r--r-- 1 yuta staff 15876 5 2 11:37 201009232329.md $ vim themes/blackburn/layouts/partials/head.html <!-- add canonical --> <link rel="canonical" href="{{ if .IsHome }}{{ .Site.Params.Canonicalurl }}{{ else }}{{ $.Params.Canonicalurl }}{{ end }}" /> $ hugo server -t blackburn -D -w ... Running in Fast Render Mode. For full rebuilds on change: hugo server --disableFastRender Web Server is available at http://localhost:1313/ (bind address 127.0.0.1)
Githubに登録し、Github Pagesを公開する
- Githubに登録する公開用静的ページを生成する。そうするとconfig.tomlで設定した
docsというディレクトリが作成される - Githubに登録不要なファイルを.gitignoreで設定する
- Githubにaddし、gh-pagesのbranchをremoteに反映
$ hugo -t blackburn $ ls docs total 1352 drwxr-xr-x 12 yuta staff 384 5 2 12:32 ./ drwxr-xr-x 12 yuta staff 384 5 2 12:26 ../ drwxr-xr-x 5 yuta staff 160 5 2 12:21 css/ drwxr-xr-x 3 yuta staff 96 5 2 12:21 img/ -rw-r--r-- 1 yuta staff 36870 5 2 12:32 index.html -rw-r--r-- 1 yuta staff 622268 5 2 12:32 index.xml drwxr-xr-x 4 yuta staff 128 5 2 12:21 js/ drwxr-xr-x 23 yuta staff 736 5 2 12:32 page/ drwxr-xr-x 210 yuta staff 6720 5 2 12:32 post/ -rw-r--r-- 1 yuta staff 28223 5 2 12:32 sitemap.xml drwxr-xr-x 4 yuta staff 128 5 2 12:32 startupai/ drwxr-xr-x 4 yuta staff 128 5 2 12:32 スタートアップaiに関わる内容を書きます/ $ cat .gitignore themes resources $ git add --all $ git push -u origin gh-pages
- 最後にgh-pagesのpull requestをmasterに反映。そうすると下記のURLでページを確認することができる。
- https://yutakikuchi.github.io/blog/
Github
- 今回作業した成果物を以下に配置
Docker for Macのメモリ制限の調整
Memory: By default, Docker Desktop for Mac is set to use 2 GB runtime memory, allocated from the total available memory on your Mac. To increase RAM, set this to a higher number; to decrease it, lower the number.
Docker for Macを使ってDocker runする際に --memory(-m) ではメモリの制限が指定できない。
Defaultの制限は2Gになっている。下記を実行しても10Gに反映されない
$ docker run -m 10g -i -t ubuntu /bin/bash
そこで、Desktopにある Preference -> Advance でMemoryの上限を調整する。Docker compose内でDeepLearningなどの重たい処理をしようとするとKilledになってしまう場合は、Memory不足であることが考えられるのでAdvanceの項目でMemory制限を解除する。下記はMemoryの制限を12Gに設定した場合。

Kerasでお試しCNN

30分でDeepLearningを実行できるようにお試しするキット。手っ取り早く始めるためにkeras(Tensorflow backend)をinstall。kerasについては下記のページで紹介されている。 尚、下にinstallのlogを残しているがkerasの前にBackendとなるTensorflowをinstallすると良い。
引用 : Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです. Kerasは,迅速な実験を可能にすることに重点を置いて開発されました. アイデアから結果に到達するまでのリードタイムをできるだけ小さくすることが,良い研究をするための鍵になります. Home - Keras Documentation
$ sudo pip install keras Cannot uninstall 'six'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. // sixを再度install $ sudo pip install keras --ignore-installed six Installing collected packages: six, numpy, h5py, keras-applications, scipy, keras-preprocessing, pyyaml, keras Running setup.py install for pyyaml ... done Successfully installed h5py-2.8.0 keras-2.2.2 keras-applications-1.0.4 keras-preprocessing-1.0.2 numpy-1.15.2 pyyaml-3.13 scipy-1.1.0 six-1.11.0 // pythonで実行するが失敗 $ python python Python 2.7.10 (default, Oct 6 2017, 22:29:07) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.31)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> from keras.models import Sequential ImportError: No module named tensorflow // tensorflowをinstall $ sudo pip install tensorflow tf-nightly Successfully installed absl-py-0.5.0 astor-0.7.1 backports.weakref-1.0.post1 enum34-1.1.6 funcsigs-1.0.2 gast-0.2.0 grpcio-1.15.0 keras-applications-1.0.5 keras-preprocessing-1.0.3 markdown-3.0 mock-2.0.0 numpy-1.14.5 pbr-4.2.0 protobuf-3.6.1 tb-nightly-1.11.0a20180923 tensorboard-1.10.0 tensorflow-1.10.1 termcolor-1.1.0 tf-nightly-1.12.0.dev20180923 werkzeug-0.14.1 wheel-0.31.1 // 再度pythonで実行 $ python python Python 2.7.10 (default, Oct 6 2017, 22:29:07) [GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.31)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> from keras.models import Sequential Using TensorFlow backend.
Kerasのexampleは下記のgithubにまとまっている。その中でもCIFAR-10の画像を分類する問題を解く。CIFAR-10は32x32pixelの6000枚x10Classの合計60000枚の画像Datasetである。60000枚のうちTrainingが50000枚、残りはEvaluation用として利用される。DownloadしたDatasetのディレクトリ以下のpickleファイルは下記のように置かれている。batches.metaには各Classの画像数とラベル名、data_batch_xにはpythonのdictionaryオブジェクト、これらを意味するのは各画像ファイル名とそれが属するClass名を含む形式で保存されている。 https://github.com/keras-team/keras/tree/master/examples CIFAR-10 and CIFAR-100 datasets

$ tree cifar-10-batches-py cifar-10-batches-py ├── batches.meta ├── data_batch_1 ├── data_batch_2 ├── data_batch_3 ├── data_batch_4 ├── data_batch_5 ├── readme.html └── test_batch
$ less read.py import pickle import sys file_name = sys.argv[1] f = file(file_name, 'rb') print pickle.load(f) $ python read.py batches.meta {'num_cases_per_batch': 10000, 'label_names': ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'], 'num_vis': 3072} $ python read.py data_batch_1 ... 'estate_car_s_001433.png', 'cur_s_000170.png']}
次にkerasのgithubからexampleを落としてくる。exampleディレクトリ配下にあるcifar10_cnn.pyの実行を行う。cifar10_cnn.pyはCIFAR10のDataset、CNN(Convolutional Neural Network)を用いた実装のsampleとなる。githubにあるサンプルをそのまま実行するとエラーが生じるので、下記のdiffを反映する必要がある。
(追記) : cifar10_cnn.py.bak は2018/09/24時点での下記githubのファイルを取得したもの。それに対して、cifar10_cnn.pyが最新の修正を加えたもの。これらのdiffを取ることで修正した箇所を明確にした。 ref : https://github.com/keras-team/keras/blob/master/examples/cifar10_cnn.py
$ git clone git@github.com:keras-team/keras.git $ cd keras/examples $ python cifar10_cnn.py ValueError: `data_format` should be `"channels_last"` (channel after row and column) or `"channels_first"` (channel before row and column). Received: None ValueError: `steps_per_epoch=None` is only valid for a generator based on the `keras.utils.Sequence` class. Please specify `steps_per_epoch` or use the `keras.utils.Sequence` class. $ diff -u cifar10_cnn.py.bak cifar10_cnn.py --- cifar10_cnn.py.bak 2018-09-24 03:24:17.000000000 +0900 +++ cifar10_cnn.py 2018-09-24 05:00:33.000000000 +0900 @@ -11,6 +11,7 @@ from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D +import numpy as np import os batch_size = 32 @@ -102,7 +103,7 @@ # set function that will be applied on each input preprocessing_function=None, # image data format, either "channels_first" or "channels_last" - data_format=None, + data_format="channels_last", # fraction of images reserved for validation (strictly between 0 and 1) validation_split=0.0) @@ -113,6 +114,7 @@ # Fit the model on the batches generated by datagen.flow(). model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), + steps_per_epoch=int(np.ceil(x_train.shape[0] / float(batch_size))), epochs=epochs, validation_data=(x_test, y_test), workers=4)
cifar10_cnn.pyでやっていることは簡単で、KerasのSequential Modelを利用して複数層を追加している。最終的に出力する分類数(Class数)は前述の通り10個、Data AugmentationをTrueにしているので画像あえて加工したものを水増ししてCNNの入力とし、Modelのロバスト性を高める目的でflagが設定されている。(もちろんFalseで実行することもできる。) batch_sizeの指定はミニバッチとして1度に取り組むデータ(画像)の数であり、全てのClassからbatch_size分のデータをランダムで取得する。1epochとはバッチサイズで指定したサンプルデータを全て使用した状態を示す。よって今回のTrainingで利用する画像数は50000枚、それを32のバッチサイズで画像数を定義するので、50000 / 32 = 1563 1563回のバッチを実施する。1バッチでパラメータを更新するので、1563回の更新が1epoch内で繰り返される。epochsで指定されている100回は1epochを100回実行すること。ややこしいので再度まとめると以下のようになる。
- batch_size : Datasetの中で何個のDataをサンプルして1回のバッチで利用するかを定義する。
- steps_per_epoch : 1epoch内において何回バッチにてパラメータを更新するかを定義する。
- 1epoch : batch_sizeをsteps_per_epoch回繰り返して全てのDatasetを参照した状態を1epochとする。
batch_size = 32 num_classes = 10 epochs = 100 data_augmentation = True
Sequential Modelのaddを利用して層を追加。例えば下記は2次元の畳み込みレイヤーを追加している。Conv2Dの最初の引数は畳み込みにおける出力フィルタの数、第二引数は3x3の畳み込み処理を適用することを意味する。input_shapeについては今回1画像のサイズが32x32、RGBなので3層あるということで、x_train.shape[1:]の値は(32, 32, 3)となっている。Sequential Modelの最初の層にはinput_shapeの情報が必ず必要。 Sequentialモデルのガイド - Keras Documentation
model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:]))
model.summary()で各LayerとOutput Shape、Paramを確認することができる。ネットワークの構成としては次のもの。INPUT => CONV * 2 => POOL => CONV *2 => POOL => DENSE * 2 => OUTPUT。CNNの基本は畳み込み層とプーリング層で構成される。間に活性化関数を挟んでいるが、層としては取り扱わない(実際にはCONV層の活性化を図っている)。
- CONV : 畳み込み層。フィルタの大きさを指定し、入力データの特徴マップを作成するために各フィルタでの畳込みの結果を出力する。
- RELU : ここではCONVの出力に対して活性化関数(ランプ関数)を適用。
- POOL : プーリング演算を適用。CONV層の後に適用され、画像データ等の入力データを扱いやすくするために重要な情報は残しながら圧縮するDown Samplingを行う。
- DENSE : 全結合層。出力層の手前で実行され、出力はClassに分類される確率といった重みになる。 出力層の数は判別したいClass数に一致する必要がある。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_5 (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ activation_7 (Activation) (None, 32, 32, 32) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 30, 30, 32) 9248 _________________________________________________________________ activation_8 (Activation) (None, 30, 30, 32) 0 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________ dropout_4 (Dropout) (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 15, 15, 64) 18496 _________________________________________________________________ activation_9 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ conv2d_8 (Conv2D) (None, 13, 13, 64) 36928 _________________________________________________________________ activation_10 (Activation) (None, 13, 13, 64) 0 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ dropout_5 (Dropout) (None, 6, 6, 64) 0 _________________________________________________________________ flatten_2 (Flatten) (None, 2304) 0 _________________________________________________________________ dense_3 (Dense) (None, 512) 1180160 _________________________________________________________________ activation_11 (Activation) (None, 512) 0 _________________________________________________________________ dropout_6 (Dropout) (None, 512) 0 _________________________________________________________________ dense_4 (Dense) (None, 10) 5130 _________________________________________________________________ activation_12 (Activation) (None, 10) 0 ================================================================= Total params: 1,250,858 Trainable params: 1,250,858 Non-trainable params: 0 _________________________________________________________________
Modelの学習にはcompileメソッドを利用する。loss関数として交差エントロピー、最適化手法としてRMSprop、評価指標としてはaccuracyを出力する。学習済みモデルと重みは指定したファイルに出力することができる。100epoch回した結果としての最終Accuracyは73.4%ということが分かる。
# Let's train the model using RMSprop model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) # Save model and weights if not os.path.isdir(save_dir): os.makedirs(save_dir) model_path = os.path.join(save_dir, model_name) model.save(model_path) print('Saved trained model at %s ' % model_path) # Score trained model. scores = model.evaluate(x_test, y_test, verbose=1) print('Test loss:', scores[0]) print('Test accuracy:', scores[1]) Epoch 99/100 1563/1563 [==============================] - 225s 144ms/step - loss: 0.8315 - acc: 0.7239 - val_loss: 0.7454 - val_acc: 0.7533 Epoch 100/100 1563/1563 [==============================] - 221s 142ms/step - loss: 0.8340 - acc: 0.7233 - val_loss: 0.7877 - val_acc: 0.7354 Saved trained model at /xxxx/git/keras/examples/saved_models/keras_cifar10_trained_model.h5 10000/10000 [==============================] - 12s 1ms/step Test loss: 0.7876939533233642 Test accuracy: 0.7354
出力されたh5のファイルからモデルを参照する事も可能。ただし、これを実行する上ではいくつかのpydot系のmoduleをpip installとgraphvizをbrew installしなしなければならないので注意が必要。plot_modelの結果は図のように出力される。
$ pip install pydot $ brew install graphviz from keras.models import load_model model= load_model('./saved_models/keras_cifar10_trained_model.h5') model.summary() from keras.utils import plot_model plot_model(model, 'model.png')

tmux : powerlineの表示ズレを解消する
表示ズレの解消

ref : tmux 2.5 以降において East Asian Ambiguous Character を全角文字の幅で表示する · GitHub file-tmux-2-7-fix-diff : https://gist.github.com/z80oolong/e65baf0d590f62fab8f4f7c358cbcc34#file-tmux-2-7-fix-diff
上図のようにtmuxのpowerline行がずっと増え続ける問題を解消する。対応方針としてはpatchを当てる。PC環境はMac、tmuxのversionは2.7を想定。patchは上記gistにversion毎にpatchが用意されている。brew edit tmuxコマンドで下記内容を追記し、brew reinstallにてpatchを適用し再度install。
// コマンドは下記を実行 $ tmux -V tmux 2.7 $ brew edit tmux // 下記を追記 def patches [ "https://gist.githubusercontent.com/z80oolong/e65baf0d590f62fab8f4f7c358cbcc34/raw/d478a099aa5074e932e3323e9b16033e13919cdf/tmux-2.7-fix.diff" ] end $ brew reinstall --build-from-source tmux ==> Summary 🍺 /usr/local/Cellar/tmux/2.7: 10 files, 705.2KB, built in 29 seconds