学習データの蓄積を加速する ABEJA Platform Annotation

ABEJA Platformについて
前回のPostでABEJAが開発しているMLOpsの課題を解決するABEJA Platformの概要について説明しました。このPostではABEJA Platformの一機能であり、学習データの蓄積を加速する ABEJA Platform Annotation について紹介します。
ABEJA Platform Annotationとは
今回はMLOpsで重要な学習データを蓄積するためのAnnotationについて書きます。そもそも学習データとは?という方もいると思うので、簡単に一言で表すと、人工知能のモデルを作るための知識・入力データと言えます。人間も学習という訓練を重ねながら脳を賢くする、このプロセスは人工知能も同じで、正しい知識から学ばなければならない。Annotationとは人工知能にとって正しい知識となるデータを作成するプロセスを示します。
よってAnnotationは非常に重要なプロセスです。なぜならば人工知能が正しい知識を得なかった場合、正しい反応をすることができません。人間も同様ですね。仮に教科書が間違っていたらそこから学んだ人も誤った知識を得て、テストで間違えてしまう。こういった事が発生しないよう、ABEJAはPlatformの一機能としてAnnotationを仕組みとして提供しています。(学習データを人工知能によって全てを自動生成することもできますが、ここでは学習データの作成は人が行うことを想定した書き方をしています。なぜならば人工知能による自動生成は誤ってしまう可能性があるためです。)

引用 : 概要 Annotationは上記AI Development Pipeline(AIに必要な開発・運用プロセスという定義)の4番目に位置するプロセスになります。
Annotation作業の具体例
学習データ作成の具体例を見てみましょう。例えば、犬と猫の画像を人工知能を使って分類したいとう問題を解くことを想定します。人は既に持っている知識から画像を見たときにそこに犬か猫が写っているかを瞬時に判別することが可能です。学習データの蓄積とは人間の知識を基に、画像の1枚ずつを目視で確認し、画像に対して犬か猫かのラベル付をしていきます。よって学習データとは下記のようと言えます。
学習データ = そもそものデータ(画像だけ) + ラベルデータ(犬か猫のラベル)


犬か猫かの判別は非常に簡単な問題です。複雑になるAnnotationとしては、犬の中でも更に犬種を分類したいとなると、多くある犬種のラベルを人間が確認しながらラベルを付与する形になります。人間が正しくこれらを判別するにはある程度の学習期間が必要だったりします。人工知能に必要な学習データ作成のために、人間が正しい知識を学習する、なんだが複雑な話です。
また上にABEJA Platform AnnotationのUIを使った作業内容の動画があります。Annotationの作業者がこのUIを使いながら作業を進めます。上では犬と猫の話をしましたが、動画中のObject Detectionのように一枚の画像の中で複数の物体を検出するための学習データを作成することもできます。
ABEJA Platform Annotationの価値は
 引用 : ABEJA Platform Annotation
引用 : ABEJA Platform Annotation
Annotationの作業において重要なポイントは下記のものになります。
- 大量のデータ作成を多数の作業者で分担し、学習データの蓄積をスムーズに行うこと
- 誤った学習データではなく、品質の高い学習データを作成をすること
- 作られた学習データが後段の学習プロセスにすぐ活用できること
ABEJA Platform Annotationは上記内容の全てをツール機能として提供しています。
1. 大量のデータ作成を多数の作業者で分担し、学習データの蓄積をスムーズに行うこと
ABEJAは多くのBPO(Business Process Outsourcing)会社と連携し、社内・外のAnnotation作業を実施する担当者を供給することができます。総勢10万人の作業者に作業を依頼することが可能なので、例えば10万枚の画像に対して何が写っているかをAnnotationするという作業についても、タスクを分散させれば作業自体は短い時間で完了を目指すことができます。
これまではData Scientistが限られた時間の中で黙々と作業を重ねられているという話も聞いたことがありますが、これからはABEJA Platform Annotationを使えば直ぐに解決する問題であり、Data Scientistは本来価値を発揮すべき作業ポイント、特に機械学習のモデル開発・チューニングに集中する事ができます。
2. 誤った学習データではなく、品質の高い学習データを作成すること
上で作成した作業に関して、BPO会社内・ABEJA社内の作業マネージャーがAnnotation作業の状況を確認することができます。全てのAnnotation作業のデータを確認することが難しい場合もあるので、そういったときはサンプリングしながらの確認になります。各作業者ごとに成果物の品質のチェックを行い、例えば品質が良くなければ次回以降の作業のためにその担当者を教育を実施するといった対応が可能になります。また最初から全てのタスクをAnnotationの作業者におまかせするのではなく、最初はトライアルタスクとして少ない数の作業を各作業者に依頼、問題ないことを確認した上で本番のタスクをアサインするというのも運用として行うことができます。
その他の方法として、難易度が高いAnnotation作業の場合は、複数人で同一データに対する作業を行い、多数決方式で正解ラベルを決定するという手段もあります。繰り返しになりますが、マネジメントの工数を掛けてでも、品質の高いデータを作成すること、人工知能に対して正しい知識をインプットすることが重要になります。
3. 作られた学習データが後段の学習プロセスにすぐ活用できること
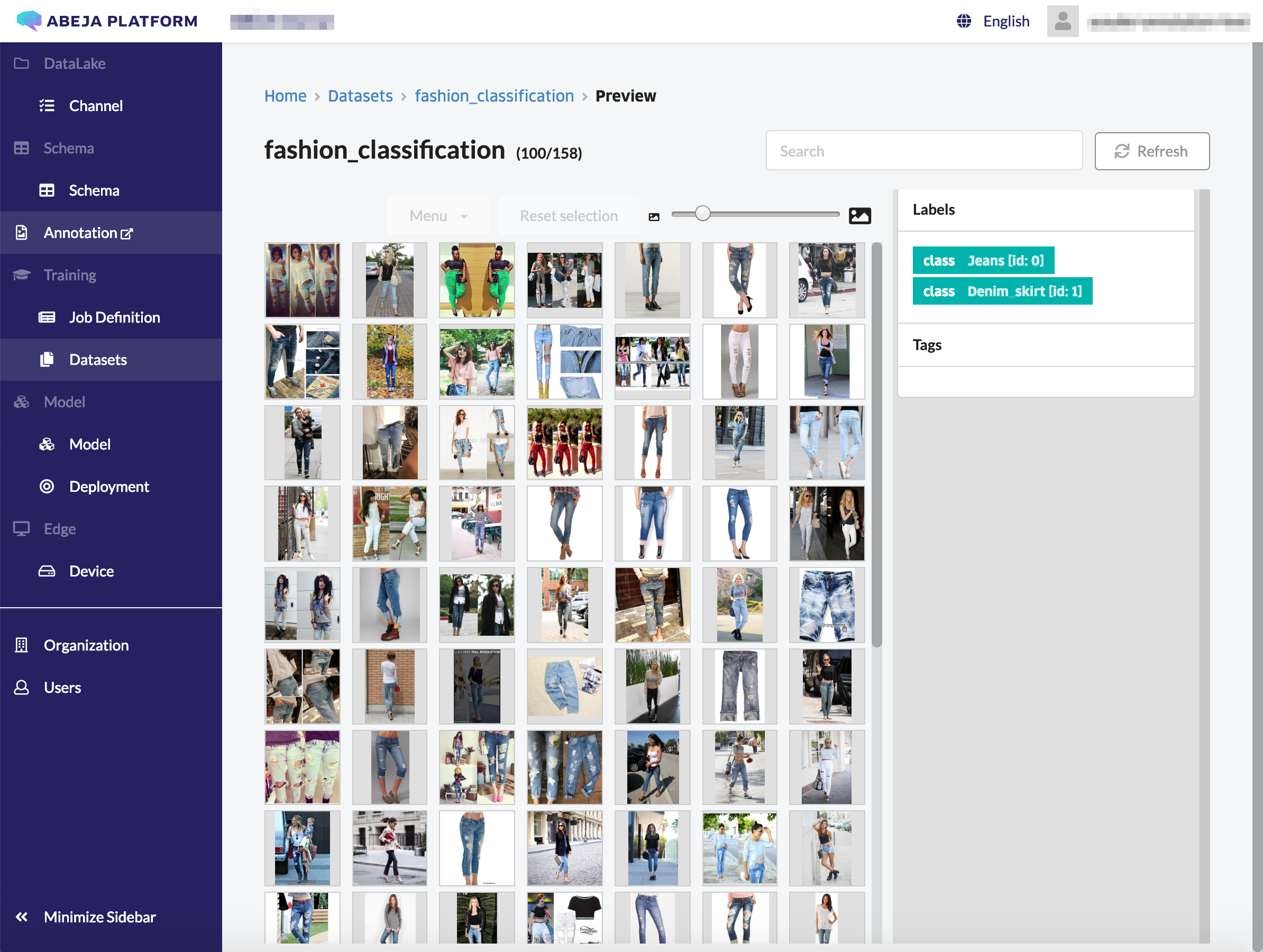
引用 : アノテーションツールの利用
上の図はFashionのitem画像が何の種類であるかを判別するためのモデルを作りたいときにAnnotationされた結果をABEJA PlatformのGUIから閲覧している状況です。付与されたラベル(例としては、JeansやDenim Skirt)でフィルタし、該当するものだけを抽出してAnnotationの結果を閲覧することもできます。
ABEJA Platformには学習データを基にした学習処理をCloud上で実行する環境を保有しています。学習データ量が大きく、または複雑なアルゴリズムを適用する場合、非常に多くの計算リソースを必要とする場合があります。ABEJA Platform Annotationで蓄積されたデータはABEJA Platformの学習基盤と直ぐに連携し、学習プロセスを実行する事ができます。 ここがまさにOnestopなServiveを展開している価値であり、ABEJA PlatformのGUIから簡単な操作で全てのMLOpsに関わる全てのプロセスの実現が可能です。
その他
本日はABEJA Platform Annotationについて説明しました。ABEJA Platform Annotationのwebサイト、ABEJA Platformの利用者向けサイト、QiitaにもABEJA PlatformおよびAnnotationの内容が記載されているので、是非下記のリンクを御覧ください。