Raspberrypi zero WとABEJA Platformを活用した侵入者通知アプリを作る
やりたいこと
家庭で簡単に防犯カメラを作りたいと思い、下記のアイテムを利用して作ってみました。 僕の家はマンションの1階にあり、5〜6畳分の庭が付いています。庭内には植物・野菜を栽培したり洗濯物を干しているので、1階に住む住人としては不審者が入ってこないかどうかが気になったりします。そこで、Raspberrypi zero W, camera module, ABEJA Platform, LINE Messaging APIを用いて、不審者が庭内で検出された場合にLINEに通知が来る仕組みを作りたいと思います。LINEに通知するのは極力リアルタイムで検知したいというのと、写真で証拠を記録し通報に利用できるというメリットがあります。家庭のセキュリティサービスを展開しているものもありますが、初期工事費用や月額でそれなりにするので、もっと簡易な防災通知ができたらと思って試してみました。今回のRaspberrypi zero Wとcamera moduleだけだと5000円ほどで実現が可能です。
必要なもの
camera moduleの撮影条件と処理の流れ

家の中からRaspberrypi zero Wとcamera moduleで庭の写真撮影を行います。撮影された写真を下記の手順で記録し、もし人間が検出された場合にのみLINE Messaging APIにてLINEに通知します。
- 家の中から庭に向けてRaspberryapi zero Wとcamera moduleを設定
- camera moduleで撮影した画像をABEJA PlatformのWebAPIに定期的にupload。cronにより5秒間隔で撮影とWebAPIにuploadを実行。
- ABEJA PlatformのWebAPIにてSSDによる物体検出を行う
- 物体検出の結果、人間が判定された場合はその画像をLINE Messaging APIを利用してPush通知する
最近はRaspberrypi側で物体検出を行うことも試されていますが、ABEJA PlatformはAIのModelのアップデートが簡単なWebUIを用いてCloud側で実現できるので、Raspberrypi側はcameraの撮影処理とWebAPIのClientを一度書いてしまえば良いようにしておきます。ただし、外部との通信回数は当然増えます。
Raspi zero Wとcamera moduleを家の中から庭に向けて設置する


家の中から外に向けてcamera moduleと接続されたRaspi zero Wを設置します。庭に向けて侵入者をチェックする向きにします。上の写真は相当適当にRaspi zero Wを設置していますが、固定できるものがあると良いです。今回はRaspiを横にして、ウルトラマンフーマでRaspiを支えています。写真は前後から撮影した様子です。
Raspi zero Wの設定手順

Raspi zero Wにsshで接続する
黄色で囲った部分の設定を進めます。Raspi zero w, camera moduleを購入します。microsdのリーダーがあれば、OSの書き込みができるので、それを活用します。初期設定についてはここでは詳しく説明を記載しません。右記のドキュメントを参照してください。 Raspberry Pi Zero(W, WH)のセットアップ - Qiita Raspi側にsshで接続して、パッケージやOSのアップデートを行います。ちなみにRaspiのpythonはv2.7.13がdefaultだったので、pyenvを使ってv3.6.8に切り替えます。また必要なpython moduleのpicameraをinstallします。
$ ssh pi@raspberrypi.local $ sudo apt-get update $ sudo apt-get upgrade $ uname -a Linux raspberrypi 4.14.71+ #1145 Fri Sep 21 15:06:38 BST 2018 armv6l GNU/Linux $ python -V Python 2.7.13 $ sudo apt-get install -y git openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev $ mkdir .pyenv $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile $ pyenv install 3.6.8 $ pyenv global 3.6.8 $ python -V Python 3.6.8 $ pip install picamera
Raspi zeroのWifiの有効化
- Raspi zeroのWifiを有効化します。
- 有効なESSIDを抽出し、/etc/wpa_supplicant/wpa_supplicant.conf に設定を下記設定を記載
$ sudo iwlist wlan0 scan | grep ESSID
$ sudo vi /etc/wpa_supplicant/wpa_supplicant.conf
country=JP
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
network={
ssid="xxxxxxx" #抽出したSSID
psk="yyyyyy" #SSIDに紐づくパスワード
}
wconfigコマンドでwlan0が有効になっていることを確認します。
wlan0 IEEE 802.11 ESSID:"xxxxxx"
Mode:Managed Frequency:2.412 GHz Access Point: yyyyy
Bit Rate=52 Mb/s Tx-Power=31 dBm
Retry short limit:7 RTS thr:off Fragment thr:off
Power Management:on
Link Quality=37/70 Signal level=-73 dBm
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:1 Invalid misc:0 Missed beacon:0
camera moduleの有効化
Raspi側でraspi-configコマンドにて有効化。5 Interfacing Options Configure connections to peripherals を選択して、camera moduleをenableにします。vcgencmd get_cameraコマンドでsupported=1, detected=1となればcamera moduleの利用がOKな状態です。
$ sudo raspi-config 5 Interfacing Options Configure connections to peripherals P1 Camera Enable/Disable connection to the Raspberry Pi Camera [enable]を選択する $ vcgencmd get_camera supported=1 detected=1
テストコマンドで写真撮影をしてみる
raspistillコマンドで撮影と保存をしてみます。問題なくRaspi上で撮影・保存することができました。
$ raspistill -w 1280 -h 800 -o image.jpg $ ls -la image.jpg -rw-r--r-- 1 pi pi 651162 Aug 25 04:34 image.jpg
撮影処理の設定
以下のPython Scriptをcronなどに仕込んでおいて定期的に写真を撮影し、それをABEJA PlatformのAPIにrequestします。ABEJA PlatformのAPI側では受け取った画像をSSDの物体検出にかけます。ABEJA Platformは学習済みモデルを簡単にWebAPIとして作成することができるので、次章で作成したendpointを下記処理に加える必要があります。
import requests import picamera import time # endpoint付け足し url = 'https://abeja-internal.api.abeja.io/deployments/xxxxxxxx' user = 'user-xxxxxxxx' access_token = 'yyyyyy' headers = {'Content-Type': 'application/octet-stream'} with picamera.PiCamera() as camera: camera.resolution = (1280, 800) camera.rotation = 270 camera.start_preview() time.sleep(2) camera.capture('person_detect.jpeg') camera.stop_preview() files = {'upload_file' : open('./person_detect.jpeg', 'rb') } r = requests.post(url, files=files, auth=(user, access_token), headers=headers) print(r.content)
ABEJA Platformを使ったSSDによる人物検出

黄色で囲った部分の設定を進めます。 ABEJA Platformとは? ABEJAが開発するcloudを用いたAIの開発・運用基盤を意味します。詳しく知りたい方は以前にABEJA Platformに関するpostをしたので、そちらをご確認ください。ABEJA Platform上でSSDを使った物体検出・人物検出を行い、人物が検出された場合はLINE Messaging APIを使った通知をするという流れを作ります。SSDの物体検出モデルのソースコードと学習済みモデルは下記に存在します。
- https://github.com/rykov8/ssd_keras
- https://mega.nz/#F!7RowVLCL!q3cEVRK9jyOSB9el3SssIA
- weights_SSD300.hdf5
- weights_300x300_old.hdf5
ABEJA Platform上でSSDを動かす



ABEJA Platform上でjupyter notebookを操作することが可能なので、ssd_kerasや上で取得したweightファイルをuploadします。ssd_keras内にある SSD.ipynb というファイルをjupyter上で開けば実行することができます。このSSD.ipynbを拡張して、人を検出したときのみ次の処理に回すような設定をしました。サンプルは次のipynbになります。security-notification/SSD.ipynb at master · yutakikuchi/security-notification · GitHub
上で動作確認をし、SSD.ipynbの内容をABEJA Platform上のWebAPIとして実行するにはipynbの内容をモデルハンドラーとして実装、実行環境にモデルと実行ファイルをDeployする必要があります。Deploy後はABEJA PlatformのWebAPIのEndpointから画像ファイル取得、SSDのモデルに適用する事ができるようになります。モデルハンドラーの実装については下記に記載されています。
モデルハンドラー関数 for 19.04 :: ABEJA Platform Developers
LINEにpush通知を送る
Push通知先のChannel初期設定
LINEにpush通知を送るためには、https://developers.line.biz/console/ にてMessaging API用のchannel登録をする必要があります。 channel登録完了後に以下の情報をconsoleから抽出し、下記のAPIに対してrequestを送付するためのheaderやbody情報に加えます。
- Access Token :
アクセストークン(ロングターム)と記載されている項目 - To(送付先) :
Your user ID
またchannelの基本情報画面にBotのQRコードが掲載されるので、必ず友達として追加する必要があります。Push通知のメッセージは追加されたBot側のアカウントにメッセージと画像が表示されます。
LINE Messaging APIにRequestする

黄色で囲った部分の設定を進めます。 LINE Messaging APIを利用してLINEに対してPush通知をします。LINEへのMessaging pushを行うにはbinaryのpostではなく、画像をURLを必要とします。よってABEJA Platform Datalakeに人物検出をされた場合は画像をアップロードし、画像のURLを発行し、そのURLを基にLINEのAPIに対してpushします。ここではABEJA PlatformのDatalakeについては特に記載をしません。
- Endpoint :
https://api.line.me/v2/bot/message/push - Content-Type :
application/json - Authorization :
Bearer <Access Token> - Request Body : JSON format
下記にLINEへのpush通知のサンプルコードを記載します。このサンプルコードをABEJA PlatformのWebAPIのロジックの中に加えます。
import requests import json headers = { "Content-Type": "application/json", "Authorization": "Bearer <Access Token>" } body = { "to" : "xxxxxxx", "messages":[ { "text": "【緊急通知】怪しいやーつがご自宅の庭に侵入しています", "type": "text" }, { "type": "image", "originalContentUrl" : "https://xxxxxxx", "previewImageUrl" : "https://xxxxxxx" } ] } response = requests.post( 'https://api.line.me/v2/bot/message/push', json.dumps(body), headers=headers )
LINEへのpush通知の結果
人が検出された場合のみLINEにpush通知が来るようになりました。(注)smileのアイコンは自動的に付与されません。SSDで検出されたbounding boxも表示されてpush通知されています。侵入者が庭にいたという証拠も写真として押させることができたので、これで目的が達成です。ただし、夜など暗い撮像条件下ではほとんど反応しない、本当の住人を顔判定で通知の除外対象としたかったのですが、現時点での課題は多くあります。

ラーメン二郎分類器 : ABEJA Platformを使ってサービス公開するぞ
ラーメン二郎分類器

引用 : ラーメン二郎 三田本店 (らーめんじろう) - 三田/ラーメン | 食べログ
皆さん、ラーメン二郎は好きですか? 好きですよね? 僕は大学の目の前にラーメン二郎があったので足繁く通っていました。しかし、ラーメン二郎初心者にとっては、麺の画像を見て、それが「ラーメン二郎」なのか「長崎ちゃんぽん」なのかが見分けが付きづらいと思います。よってDeepLearningを用いて、それらの分類を自動化する仕組みをABEJA Platformを使って実装する方法について記載します。データのcrawlingなどの実装は必要ですが、学習に関してはtemplateという機能を利用するとノンプログラミングでもモデル作成が可能なので、以下の作業時間はおおよそ10分で完了できます。
既にABEJA Platform、ABEJA Platform Annotationについては記事にしているので、以下のリンクも参考にしてください。
必要なもの
- python
- version 3.6.6 (versionはこれに限定されず、実行可能)
- 「ラーメン二郎」と「長崎ちゃんぽん」の麺が写っている写真、学習データ
- icrawlerを利用してABEJA PlatformのDatalakeに結果を格納
- ABEJA Platform
- ABEJA Platformのアカウントを必要とします。
- ご利用されたい方は下記の問い合わせよりお願いいたします。
- https://abejainc.com/platform/ja/contact/
- ABEJA Platform SDK
- ラーメン二郎への愛情
- 愛情があると良し。ただし、必須ではない
手順
- ABEJA Platformのjupyter notebookを利用する
- icrawlerで画像を保存する
- 学習データのメタ情報をjsonとして作成
- ABEJA Platform Datalakeへchannelを作成
- ABEJA Platform Datalakeへ画像を登録
- ABEJA Platform Datasetの作成、学習データをimportする
- ABEJA PlatformのTemplateを用いて学習、Deployする
手順の図解
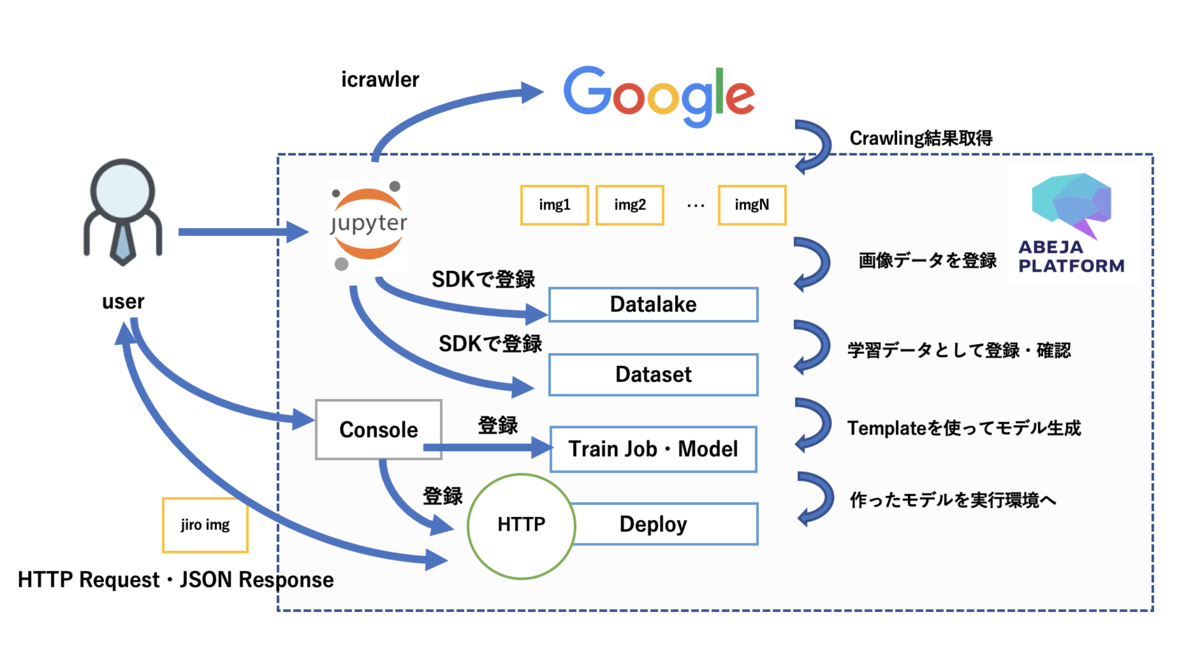
ラーメン二郎分類器をつくる
ABEJA Platformのjupyter notebookを利用する
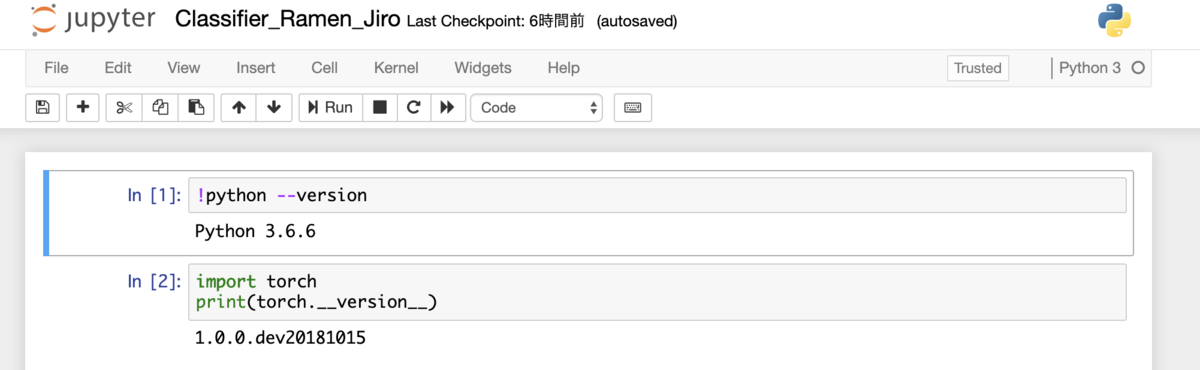
ABEJA PlatformはCloud上でMLOpsのプロセスを実行することが可能、いわゆる機械学習の開発・運用基盤です。ABEJA Platformのアカウントを持っていれば、Consoleという管理画面が使え、その上でjupyter notebookで作業を進めることができます。 https://console.abeja.io アカウントがある方はこちらからログイン後にjupyter notebookを使うことができます。アカウントが無い方は https://abejainc.com/platform/ja/contact/ から問い合わせをお願いいたします。
上の図はABEJA Platform上でjupyter notebookを扱っている例です。尚、以下では各種実行に必要な変数がありますが、Consoleから全て確認ができますので、確認した値をご利用ください。
- organization_id = 'xxxxxxxxx' - user_id = 'user-xxxxxxxxx' - personal_access_token = 'xxxxxxxxx' - channel_id = 'xxxxxxxxx'
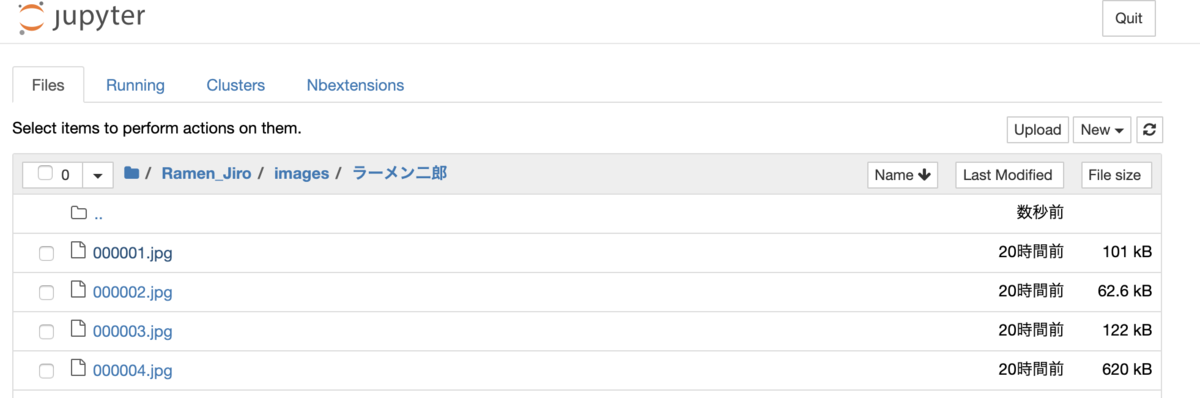
icrawlerで画像を保存
from icrawler.builtin import GoogleImageCrawler # getting crawling data using icralwer # search query queries = [u'ラーメン二郎', u'長崎ちゃんぽん'] for q in queries: print(q) crawler = GoogleImageCrawler(storage = {'root_dir' : 'images/'+q}) crawler.crawl(keyword = q, max_num = 200)
今回はicrawlerを利用してGoogleの検索結果からラーメン二郎と長崎ちゃんぽんの画像を引っ張ってきます。まずはABEJA Platformでのnotebookの作業配下に images/{query} というディレクトリを切って画像を保存します。それぞれ200枚ずつのデータを蓄積します。sample codeは上記のものになります。sample codeを実行すると上図のようにjupyter notebookの作業ディレクトリ配下に画像が保存されます。
学習データのメタ情報をjsonとして作成
import json # create training categories data json_data['categories'] = {} category_data = [] category_data.append({'labels':[], 'category_id':1, 'name':'Ramen'}) labeled_data = [] labeled_data.append({'label_id':1, 'label':'Ramen_jiro'}) labeled_data.append({'label_id':2, 'label':'Nagasaki_Champon'}) labeled_data.append({'label_id':3, 'label':'Other'}) json_data['categories'] = category_data json_data['categories'][0]['labels'] = labeled_data # format is below # {"categories": [{"labels": [{"label_id": 1, "label": "Ramen_jiro"}, {"label_id": 2, "label": "Nagasaki_Champon"}, {"label_id": 3, "label": "Other"}], "category_id": 1, "name": "Ramen"}]} json.dump(json_data, open('categories.json','w'))
学習データを作成するために、icrawlerによって集めた画像が何のラベルを持つべきかの定義を行います。定義としてはlabel_id : 1〜3、それぞれにRamen_jiro、Nagasaki_Champon、Otherという形でラベル名を持ちます。このあとの作業としてABEJA Platform Datalakeに画像を登録しつつ、その画像が何のLabelなのかを一緒に登録します。これでcrawlingした結果をそのまま学習データとして活用する事ができます。もちろん、Datalakeに登録した画像をAnnotationして人の目を通して学習データを手作業で作成することもできます。ただし、ここでは省略。
ABEJA Platform Datalakeへchannelを作成
A Sample tutorial — ABEJA Dataset Library documentation
from abeja.datalake import Client as DatalakeClient from abeja.datalake.storage_type import StorageType # create ABEJA Platform Datalake channel organization_id = 'xxxxxxxxx' user_id = 'user-xxxxxxxxx' personal_access_token = 'xxxxxxxxx' credential = { 'user_id': user_id, 'personal_access_token': personal_access_token } datalake_client = DatalakeClient(organization_id=organization_id, credential=credential) name = 'Ramen_jiro' description = 'a channel for ramen_jiro' channel = datalake_client.channels.create(name, description, StorageType.DATALAKE.value)
収集したラーメン二郎と長崎ちゃんぽんの画像データをABEJA Platform DatalakeというObject Storageに保存します。。まずDatalakeに対しての手順として、1.channelを作成する、2.channelにデータを登録する が必要になります。Datalakeへの操作としてはABEJA Platform SDKがあるので、それを利用すると簡単なpythonコードで操作が可能になります。SDKのドキュメント、チュートリアルは上のURLにあります。上のsample codeを実行するとDatalakeにchannelを作成します。channelはデータソースを定義するために作成します。今回で言うラーメンの画像とラベルデータの保存先となります。
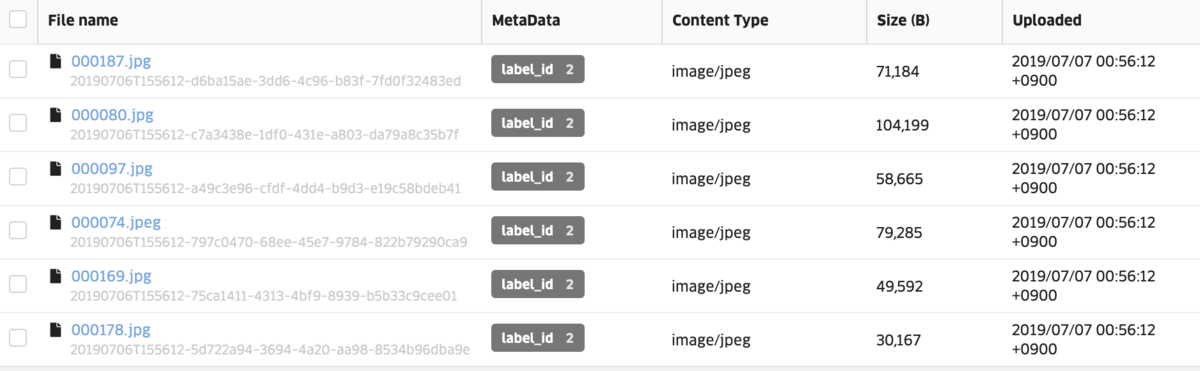
ABEJA Platform Datalakeへ画像を登録
import glob from abeja.datalake import Client as DatalakeClient # upload images client = DatalakeClient() organization_id = 'xxxxxxxxx' channel_id = 'xxxxxxxxx' datalake_client = DatalakeClient(organization_id=organization_id) channel = datalake_client.get_channel(channel_id) queries = [{'name':u'ラーメン二郎', 'label_id':1},{'name':u'長崎ちゃんぽん','label_id':2}] for q in queries: files = glob.glob('images/'+q['name']+'/*') metadata = {'label_id':q['label_id']} for file in files: res = channel.upload_file(file, metadata=metadata)
jupyter notebook上でicrawlerがimages/{query}という形で保存先のディレクトリでデータを切り分けたので、それぞれの画像データと正解データとなるlabel_idをDatalakeに登録します。sample codeは上記のものになります。sample codeを実行すると上図のようにDatalakeのchannelに画像データとlabel_idのデータが閲覧可能になります。
ABEJA Platform Datasetの作成、学習データをimportする
import json from abeja.datasets import Client # create dataset ORGANIZATION_ID = 'xxxxxxxxx' client = Client(organization_id=ORGANIZATION_ID) props = json.load(open('categories.json','r')) dataset = client.datasets.create(name='ramen_jiro_dataset', type='classification', props=props)
Datalakeに登録したデータを学習データとして扱う、目視で確認するためにDatasetという機能を利用します。まずはdatasetを作成します。学習データのメタ情報をjsonとして作成 のパートで保存したcategories.jsonというファイルをここで利用します。
from abeja.datalake import Client as DatalakeClient # get datalake files # import from datalake to dataset client = DatalakeClient() organization_id = 'xxxxxxxxx' channel_id = 'xxxxxxxxx' datalake_client = DatalakeClient(organization_id=organization_id) channel = datalake_client.get_channel(channel_id) for file in channel.list_files(): source_data = [ { 'data_type': file.content_type, 'data_uri': file.uri, } ] attributes = { 'classification': [ { 'category_id': 1, 'label_id': file.metadata['label_id'] } ] } dataset_item = dataset.dataset_items.create(source_data=source_data, attributes=attributes)
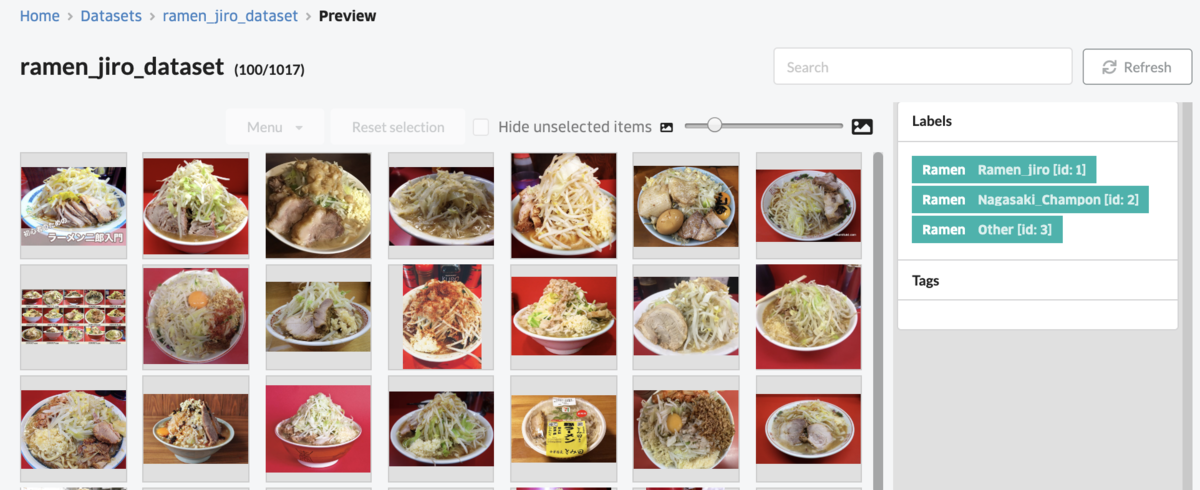
次にDatalakeからDatasetに対象のデータをimportします。上記sample codeを実行するとDatasetの画面から一覧を確認することができます。画面右にあるlabelをクリックするとラーメン二郎、長崎ちゃんぽんのそれぞれのDatasetを見ることができます。
ABEJA PlatformのTemplateを用いて学習、Deployする
Templateの中身については上記githubに詳細が記載されています。 This template uses transfer-learning from VGG16 ImageNet. モデルはVGG16の転移学習によって行われています。
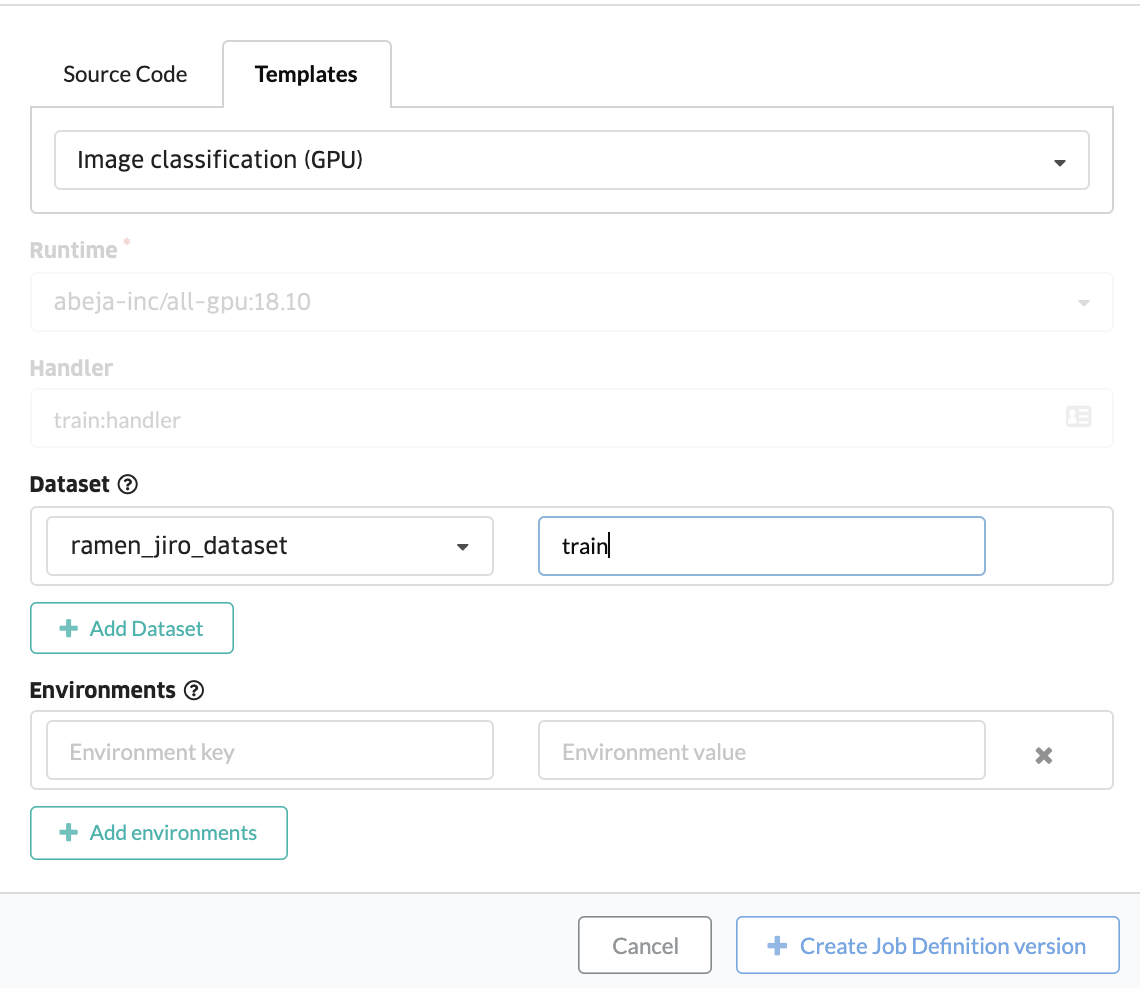
ABEJA PlatformのConsoleを使って、学習のTemplateを利用します。ConsoleのJob Definitionというメニューから学習jobを設定できます。Template機能を使う場合は、表示された画面の中で Templates というタブを選択してください。ソースコードを登録したい場合は Source Code というメニューを選択しますが、今回はSource Codeは使用しません。


続けてtrain jobを作成します。先程登録したTemplateのjobをこちらの画面で登録していきます。上記画面にて項目を選択するだけで実行が可能です。しばらくするとtrain jobが停止し、学習が完了した状態を確認することができます。

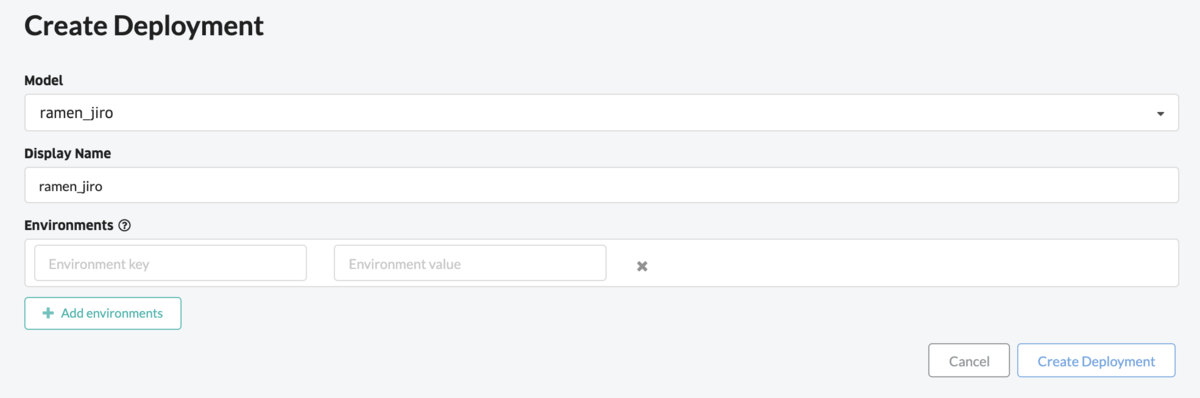
Train jobと同様にDeployについてもノンプログラミングで行います。Deployの機能は作成したモデルを実行できる環境に配置することです。ここではWebAPIとして実行する例を記載していきます。上図ではまずはTrain jobで作成されたモデルを定義しています。作成されたモデルをDeployするための設定も付け加えます。これでモデルを実行できる環境が整いました。
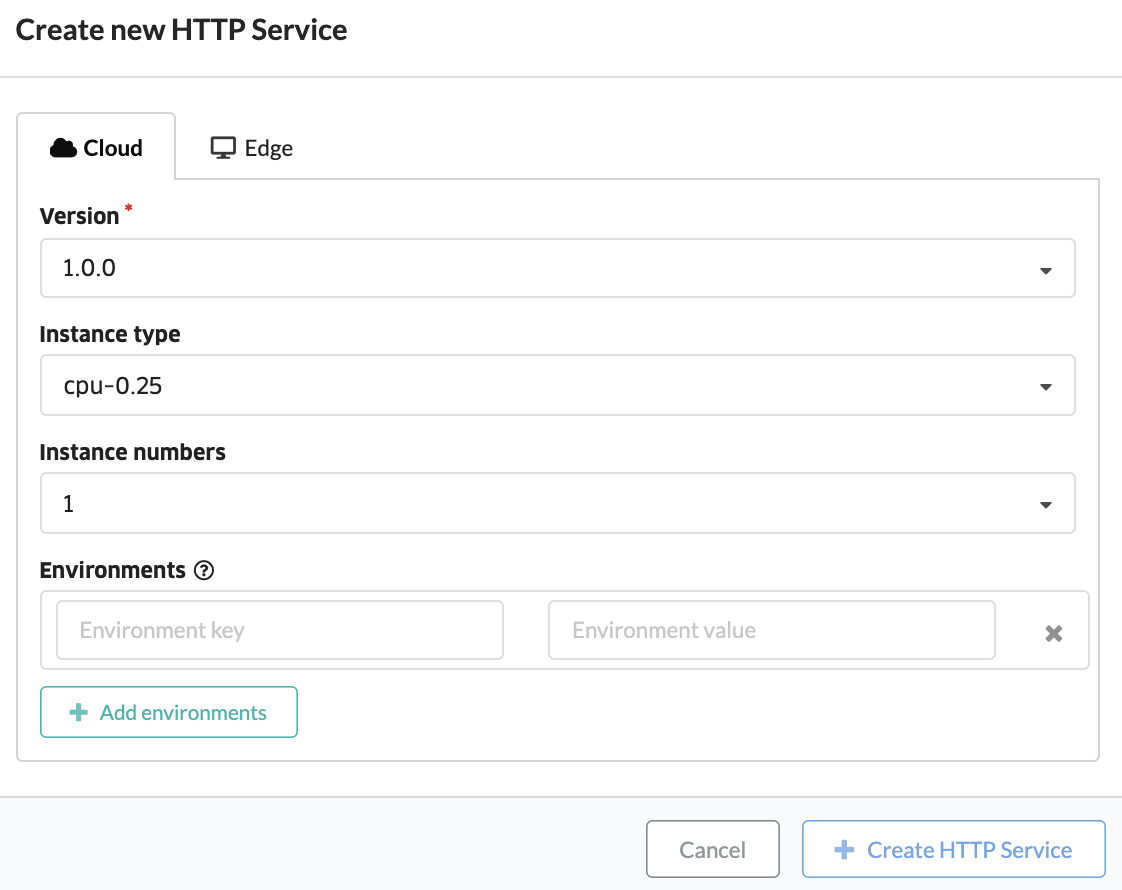
DeployされたモデルをWebAPIとして呼び出すための設定を加えます。Deployの画面で 必要な項目を選択、Create HTTP Service ボタンを押下します。
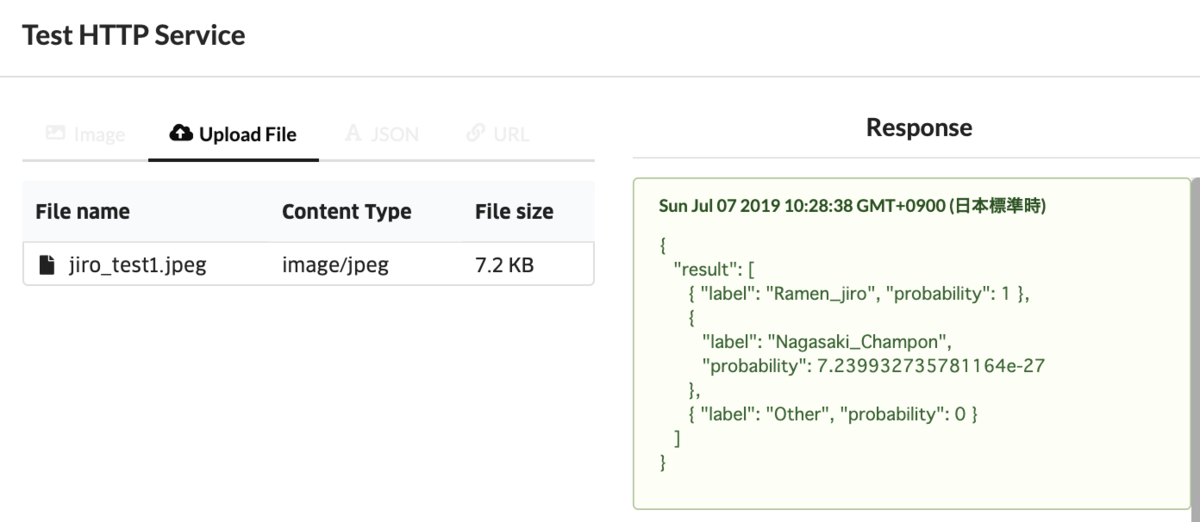
{ "result": [ { "label": "Ramen_jiro", "probability": 1 }, { "label": "Nagasaki_Champon", "probability": 7.239932735781164e-27 }, { "label": "Other", "probability": 0 } ] }
作成されたHTTP Serviceに対してテストを実施してみます。ラーメン二郎の画像をアップロードし、それに対してJSONフォーマットでの結果が返ってくることを確認します。上記のようにRamen_jiroであるProbabilityが1となっているので、100%ラーメン二郎だという回答になっています。あとはHTTP Serviceを外部向けのサービスとして公開するだけです。Deployの画面でAdd Endpoint というボタンを押下すると外部向けのEndpointが作成されるので、作成されたEndpointに対して画像をpostすると上記テストと同じようにJSONフォーマットの結果が返ってきます。
cURL command curl -X POST \ -u user-xxxxxxxxx \ -H "Content-Type: image/jpeg" \ --data-binary @jiro_test1.jpg \ https://abeja-internal.api.abeja.io/deployments/yyyyyyyy
{ "result": [ { "label": "Ramen_jiro", "probability": 1 }, { "label": "Nagasaki_Champon", "probability": 7.239932735781164e-27 }, { "label": "Other", "probability": 0 } ] }
最後に
いかがでしたでしょうか。ABEJA Platform上でjupyter notebook、consoleを使いこなし、更にはモデルのアルゴリズムの中身を知らなくてもノンプログラミングでサービス化までできます。本日の内容は本当に簡単なものを紹介しましたが、これらの機能を利用することで様々なサービスをABEJA Platform上で公開することができます。その他、多くのドキュメントがあるので、是非下記URLを参照してください。
学習データの蓄積を加速する ABEJA Platform Annotation

ABEJA Platformについて
前回のPostでABEJAが開発しているMLOpsの課題を解決するABEJA Platformの概要について説明しました。このPostではABEJA Platformの一機能であり、学習データの蓄積を加速する ABEJA Platform Annotation について紹介します。
ABEJA Platform Annotationとは
今回はMLOpsで重要な学習データを蓄積するためのAnnotationについて書きます。そもそも学習データとは?という方もいると思うので、簡単に一言で表すと、人工知能のモデルを作るための知識・入力データと言えます。人間も学習という訓練を重ねながら脳を賢くする、このプロセスは人工知能も同じで、正しい知識から学ばなければならない。Annotationとは人工知能にとって正しい知識となるデータを作成するプロセスを示します。
よってAnnotationは非常に重要なプロセスです。なぜならば人工知能が正しい知識を得なかった場合、正しい反応をすることができません。人間も同様ですね。仮に教科書が間違っていたらそこから学んだ人も誤った知識を得て、テストで間違えてしまう。こういった事が発生しないよう、ABEJAはPlatformの一機能としてAnnotationを仕組みとして提供しています。(学習データを人工知能によって全てを自動生成することもできますが、ここでは学習データの作成は人が行うことを想定した書き方をしています。なぜならば人工知能による自動生成は誤ってしまう可能性があるためです。)

引用 : 概要 Annotationは上記AI Development Pipeline(AIに必要な開発・運用プロセスという定義)の4番目に位置するプロセスになります。
Annotation作業の具体例
学習データ作成の具体例を見てみましょう。例えば、犬と猫の画像を人工知能を使って分類したいとう問題を解くことを想定します。人は既に持っている知識から画像を見たときにそこに犬か猫が写っているかを瞬時に判別することが可能です。学習データの蓄積とは人間の知識を基に、画像の1枚ずつを目視で確認し、画像に対して犬か猫かのラベル付をしていきます。よって学習データとは下記のようと言えます。
学習データ = そもそものデータ(画像だけ) + ラベルデータ(犬か猫のラベル)


犬か猫かの判別は非常に簡単な問題です。複雑になるAnnotationとしては、犬の中でも更に犬種を分類したいとなると、多くある犬種のラベルを人間が確認しながらラベルを付与する形になります。人間が正しくこれらを判別するにはある程度の学習期間が必要だったりします。人工知能に必要な学習データ作成のために、人間が正しい知識を学習する、なんだが複雑な話です。
また上にABEJA Platform AnnotationのUIを使った作業内容の動画があります。Annotationの作業者がこのUIを使いながら作業を進めます。上では犬と猫の話をしましたが、動画中のObject Detectionのように一枚の画像の中で複数の物体を検出するための学習データを作成することもできます。
ABEJA Platform Annotationの価値は
 引用 : ABEJA Platform Annotation
引用 : ABEJA Platform Annotation
Annotationの作業において重要なポイントは下記のものになります。
- 大量のデータ作成を多数の作業者で分担し、学習データの蓄積をスムーズに行うこと
- 誤った学習データではなく、品質の高い学習データを作成をすること
- 作られた学習データが後段の学習プロセスにすぐ活用できること
ABEJA Platform Annotationは上記内容の全てをツール機能として提供しています。
1. 大量のデータ作成を多数の作業者で分担し、学習データの蓄積をスムーズに行うこと
ABEJAは多くのBPO(Business Process Outsourcing)会社と連携し、社内・外のAnnotation作業を実施する担当者を供給することができます。総勢10万人の作業者に作業を依頼することが可能なので、例えば10万枚の画像に対して何が写っているかをAnnotationするという作業についても、タスクを分散させれば作業自体は短い時間で完了を目指すことができます。
これまではData Scientistが限られた時間の中で黙々と作業を重ねられているという話も聞いたことがありますが、これからはABEJA Platform Annotationを使えば直ぐに解決する問題であり、Data Scientistは本来価値を発揮すべき作業ポイント、特に機械学習のモデル開発・チューニングに集中する事ができます。
2. 誤った学習データではなく、品質の高い学習データを作成すること
上で作成した作業に関して、BPO会社内・ABEJA社内の作業マネージャーがAnnotation作業の状況を確認することができます。全てのAnnotation作業のデータを確認することが難しい場合もあるので、そういったときはサンプリングしながらの確認になります。各作業者ごとに成果物の品質のチェックを行い、例えば品質が良くなければ次回以降の作業のためにその担当者を教育を実施するといった対応が可能になります。また最初から全てのタスクをAnnotationの作業者におまかせするのではなく、最初はトライアルタスクとして少ない数の作業を各作業者に依頼、問題ないことを確認した上で本番のタスクをアサインするというのも運用として行うことができます。
その他の方法として、難易度が高いAnnotation作業の場合は、複数人で同一データに対する作業を行い、多数決方式で正解ラベルを決定するという手段もあります。繰り返しになりますが、マネジメントの工数を掛けてでも、品質の高いデータを作成すること、人工知能に対して正しい知識をインプットすることが重要になります。
3. 作られた学習データが後段の学習プロセスにすぐ活用できること
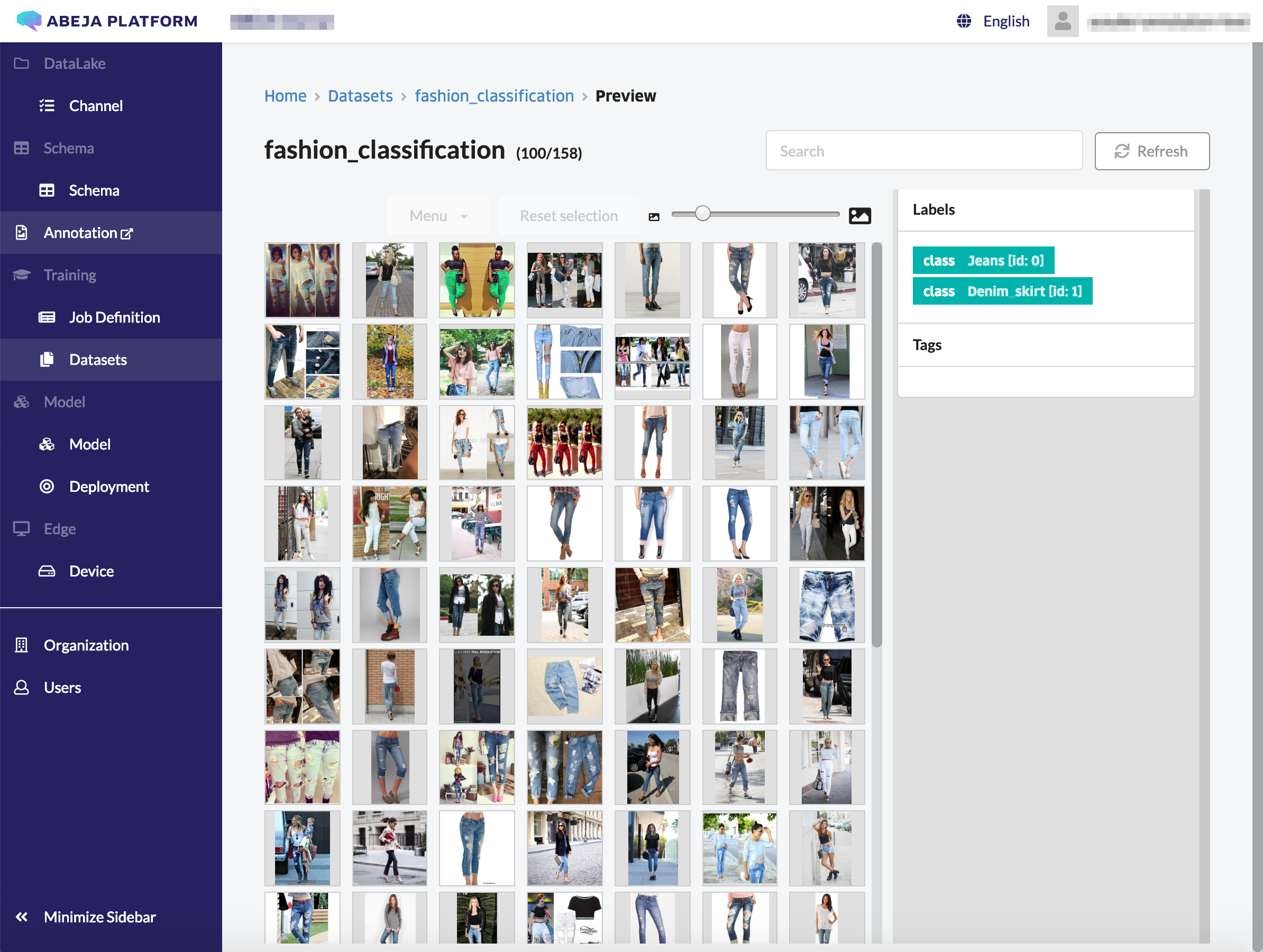
引用 : アノテーションツールの利用
上の図はFashionのitem画像が何の種類であるかを判別するためのモデルを作りたいときにAnnotationされた結果をABEJA PlatformのGUIから閲覧している状況です。付与されたラベル(例としては、JeansやDenim Skirt)でフィルタし、該当するものだけを抽出してAnnotationの結果を閲覧することもできます。
ABEJA Platformには学習データを基にした学習処理をCloud上で実行する環境を保有しています。学習データ量が大きく、または複雑なアルゴリズムを適用する場合、非常に多くの計算リソースを必要とする場合があります。ABEJA Platform Annotationで蓄積されたデータはABEJA Platformの学習基盤と直ぐに連携し、学習プロセスを実行する事ができます。 ここがまさにOnestopなServiveを展開している価値であり、ABEJA PlatformのGUIから簡単な操作で全てのMLOpsに関わる全てのプロセスの実現が可能です。
その他
本日はABEJA Platform Annotationについて説明しました。ABEJA Platform Annotationのwebサイト、ABEJA Platformの利用者向けサイト、QiitaにもABEJA PlatformおよびAnnotationの内容が記載されているので、是非下記のリンクを御覧ください。
MLOpsの課題を解くABEJA Platform
はじめに
私は日本のAI Startupの 株式会社ABEJA という会社に所属しています。ABEJAの中では主に製品開発・事業開発を携わっています。所属している人間が言うのもアレですが、ABEJAの製品、その裏側で使われている技術は state-of-the-art なものであり、それを作っている・売っている両方のメンバーが非常に優秀です。
今日は簡単にABEJA Platformの紹介をしていきたいと思います。このPostをきっかけとして何度かABEJA Platformに関する記事を投稿する予定なので、機械学習をビジネスに実装する上でのMLOpsに課題を持っている方はそれを解決するための手段として是非ABEJA Platformをご利用いただきたいと思います。
ABEJA Platformとは
それでは本題に入ります。ABEJA Platformとは何か? ABEJA Platformの機能を簡単に表現すると表題の通りMLOpsの課題を解くAwesomeな製品になっています。(機能以外にも機械学習ビジネスを展開するためのPlatformでもありますが、それは後日紹介します。) 現在におけるData Scientistの方々の業務領域の定義が広く・曖昧な状況が続き、MLOpsに関わる多くの作業を彼ら自身が実施しなければならないケースがあります。しかし、これは本当に正しい状態と言えるでしょうか。Data Scientistに一番求めるスキルを機械学習モデルの開発・チューニングと定義された場合、機械学習のモデルをDeliveryするためのシステム運用のインフラを構築することを依頼するのは守備範囲を広げてしまい、本来求めたかったミッションから遠ざかります。
機械学習のモデル開発・運用に必要とされる人間が関わるプロセス(ABEJAが言うAI Development Pipeline)を最小のコストで実現すること、Data Scientistのコアコンピタンスを明確に定義し、開発・チューニングに専念してもらうこと、その結果いち早くビジネスに対して機械学習の導入を進めること、このような目的でABEJA Platformの開発が行われています。ABEJA PlatformはOnestopな製品であり、非常にシンプルです。多くのサービスを組み合わせてAI Development Pipelineの実行をする必要がないので、全ての操作を一つの管理画面から実行することが可能です。

引用 : https://abejainc.com/platform/
ABEJA Platformとの連携
ABEJA PlatformはCloudをベースとした機械学習の開発・運用基盤と言えます。最近においてはCloudとお客様のOn-premisesを連携するための開発も進めており、今後多くの皆さんにご利用いただくための最適な環境を提供したいと考えています。On-premisesな環境の一つとして、CloudとIoTデバイス(Edge)との連携が可能なようにしています。例えば、データの取得元・機械学習モデルの実行環境としてはIoTデバイスで行い、学習データの蓄積・モデルの生成はCloudで行うという、使い分けをすることもできます。
今後あらゆる場面でIoTデバイスの導入が進むことは明らかなので、ABEJAとしてもEdgeとの連携については多くのビジネス機会があると考えています。( 下記図に記されているように、上りのIoT、下りのIoTの連携が進む。上りのIoTとはデバイスからクラウドにデータを預ける、下りのIoTで預けたデータから生成された新しい価値をデバイス側に届けるという意味合い)

引用 : https://abejainc.com/platform/
最後に
いかがでしたでしょうか。機械学習のモデル開発をやられたことがある方は、MLOpsの経験者は共感いただけるポイントが多かったと思います。現在はABEJA Platformの公式ドキュメントを一般公開しているので、是非ご覧頂きたいと思います。
またQiitaにも情報を公開していますので、より実活用のイメージを持っていただければと思います。今日のpostは第一回目なので、今後複数回に渡ってABEJA Platformを紹介していきます。繰り返しになりますが、興味を持たれた方は是非問い合わせフォームから依頼を投げていただければと思います。https://abejainc.com/platform/ja/contact/ こちらからお願いいたします。
暗号通貨の価格推移データをGoogle Spreadsheetを使ってHackする
やること
- Google Spreadsheetだけで暗号通貨の価格推移データを取得する
- 取得したデータを基にデータの可視化、分析を行う。※ 今回のentryではその準備までを対象とする
Ref
- Google Spreadsheetに暗号通貨の価格推移データを表示するrepositoryを下記に設置
- GitHub - yutakikuchi/crypto-currency-googlespreadsheet
Hack方法① : GoogleFinance関数
- Google Spreadsheetのデフォルト関数である
GoogleFinanceを利用する- 関数例 :
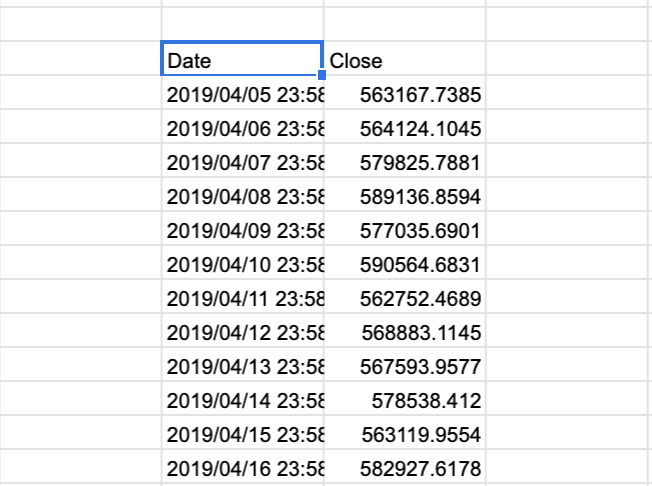
=GoogleFinance("CURRENCY:BTCJPY" , "price", TODAY()-10,TODAY(), "DAILY") - ただし、この方法ではBTCしか出力ができない
- 関数例 :
Hack方法② : IMPORTXML関数
- Google Spreadsheetのデフォルト関数である
IMPORTXMLを利用して、https://coinmarketcap.com/ja/currencies/ からデータを取得する- 今回のHack方法。Google Spreadsheetだけでcoinmarketcapからデータをスクレイプする
- またGoogleFinance関数を利用してUSD to JPYも計算している

- 下記にSampleのGoogle Spreadsheetを掲載。end_dateから10日間遡ってデータを取得する
- coinmarketcapで扱っている通貨であれば対応は可能
- Crypto Currency Historical - Google スプレッドシート
- ※ ただし、この方法はimportに時間が掛かる
Hack方法③ : AddonのCRYPTOFINANCEを利用
- Google Spreadsheetのaddonである
CRYPTOFINANCEを利用する

導入手順 : Hack方法② IMPORTXML(crypto-currency-googlespreadsheet)
- crypto-currency-googlespreadsheet/README.md at master · yutakikuchi/crypto-currency-googlespreadsheet · GitHub
- Google Spreadsheetを1つ用意し、sheetタブを2つ作成する
- 1つは値動きを表示するsheetタブ、もう一つは各種パラメータを設定するもの
- sheetタブの名前はそれぞれ下記のものとする
Parameter SheetCrypto Currency
- Parameter Sheetの内容は下記スクリプトを実行、Sheetに貼り付ける
python parameter_sheet.py
- Crypto Currencyの内容は下記スクリプトを実行し、Sheetに貼り付ける
python currency_table_gen.py 100
Hack方法②のGoogle Spreadsheetのサンプル
Hugo + Github PagesでMarkdownで書いた記事を公開する
Ref
Goal
- Hugoで作った静的ページをGithub Pagesで公開することを目標とする
- About GitHub Pages - GitHub Docs
- Github Pagesには2種類ある
- Projectで設定する :
https://(USERNAME).github.io/<Project> - User, Organizationで設定する :
https://(USERNAME).github.io/
- Projectで設定する :
- 今回は前者(Projectで設定する)の方法で実施する
- Hatena Blogで公開していたpostをMovable Type形式でExportして、Github Pages上にMarkdown形式で設置
- Hatena Blog : Y's note
- Export : 記事データをエクスポートできるようにしました。ブログのバックアップ等にご利用ください - はてなブログ開発ブログ
Hugo, Github Pages
MacへHugoをinstall
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.4 BuildVersion: 18E226 $ brew install hugo $ hugo version hugo version Hugo Static Site Generator v0.55.4/extended darwin/amd64 BuildDate: unknown
Movable Type型をHugoの形式(Markdown型)に変換
- Hatena Blogのpostをexportしたい
- Hatena BlogのExport機能はMovable Type型でしかできない。よってHugo形式のMarkdownに合わせる必要がある
- 以下にsampleコードがあるので、Movable Type形式から変換するように改修する
- 改修したファイルは次の名前で定義。hatena_2_hugo.rb
$ rbenv exec bundle exec ruby hatena_2_hugo.rb hatena_export.txt md_output
- md_outputのディレクトリに各post毎に
YYYYmmddHHMM.mdとして出力される
$ head -n 10 md_output/_posts/201904292103.md --- title: "Docker for Macのメモリ制限の調整" date: 2019-04-29T21:03:52+00:00 category : [etc] canonicalurl: http://yut.hatenablog.com/entry/2019/04/29/210352 --- ## [etc] : Docker for Macのメモリ制限の調整
- 元のHatena Blogの検索インデックスに悪影響を及ぼさないようにMovable Typeで出力されたBASENAMEからcanonicalurlを設定している
- canonicalurlのパラメータをHugoのtemplateからparameterとして読み込むことができる
Gitの設定、Hugoのファイル構成設定
- Github Pagesでprojectの静的ページを公開する方法は3つ紹介されている
- 公開用の静的ページをmasterのdocsディレクトリ配下に置く
- 公開用の静的ページをgh-branchの直下に置く
- 公開用静的ページをmasterの直下に置く
- 今回は1.の方法で実施。
- Hugoのtemplateを作成する。ディレクトリの名前は
blog - github上に適当な名前のrepositoryを作成する
- 今回はディレクトリ名に合わせて
blogという名前で作成 - Postのソースを管理するbranchを
gh-pagesとして作成
- 今回はディレクトリ名に合わせて
- Hugoのthemeである
blackburnを利用する
$ hugo new blog $ git init blog $ cd blog $ git add --all $ git commit -m "first commit" $ git remote add origin git@github.com:yutakikuchi/blog.git $ git push -u origin master $ git checkout -b gh-pages $ cd themes $ git clone https://github.com/yoshiharuyamashita/blackburn.git $ cd ../ $ mkdir -p content/post
- hugoディレクトリの下にできる
config.tomlとcontentに対して手を加えていく。blackburnのthemeのconfig.tomlを以下のように設定
$ cat config.toml | pbcopy baseurl = "https://yutakikuchi.github.io/blog/" # Make sure to end baseurl with a '/' languageCode = "ja-jp" title = "Y's note" author = "菊池佑太" # Shown in the side menu copyright = "© 2019. All rights reserved." canonifyurls = true paginate = 10 publishDir="docs" [indexes] tag = "startup,AI" topic = "スタートアップ,AIに関わる内容を書きます" [params] # Shown in the home page brand = "Y's note" googleAnalytics = "UA-20616165-3" # CSS name for highlight.js highlightjs = "androidstudio" highlightjs_extra_languages = ["yaml"] # dateFormat = "02 Jan 2006, 15:04" dateFormat = "2006 Jan 02, 15:04" # Include any custom CSS and/or JS files # (relative to /static folder) custom_css = ["css/my.css"] custom_js = ["js/my.js"] # canonicalurl canonicalurl = "http://yut.hatenablog.com" #[params.piwikAnalytics] # siteid = 2 # piwikroot = "//analytics.example.com/" [menu] # Shown in the side menu. [[menu.main]] name = "Home" pre = "<i class='fa fa-home fa-fw'></i>" weight = 1 identifier = "home" url = "/" [[menu.main]] name = "Posts" pre = "<i class='fa fa-list fa-fw'></i>" weight = 2 identifier = "post" url = "/post/" [[menu.main]] name = "About" pre = "<i class='fa fa-user fa-fw'></i>" weight = 3 identifier = "about" url = "/about/" #[[menu.main]] # name = "Contact" # pre = "<i class='fa fa-phone fa-fw'></i>" # weight = 4 # url = "/contact/" [social] # Link your social networking accounts to the side menu # by entering your username or ID. # SNS microblogging twitter = "yutakikuchi_" # gnusocial = "*" # Specify href (e.g. https://quitter.se/yourusername) facebook = "yuta.kikuchi.007" # googleplus = "*" # weibo = "*" # tumblr = "*" # SNS photo/video sharing # Instagram = "*" # Flickr = "*" # Photo500px = "*" # Pinterest = "*" # Youtube = "*" # Vimeo = "*" # Vine = "*" slideshare = "https://www.slideshare.net/yutakikuchi58/" # SNS career oriented linkedin = "https://www.linkedin.com/in/%E4%BD%91%E5%A4%AA-%E8%8F%8A%E6%B1%A0-36291a44/" # xing = "*" # SNS news # reddit = "*" # hackernews = "*" # Techie github = "yutakikuchi" # gitlab = "*" # bitbucket = "*" # stackoverflow = "*" # serverfault = "*" # Gaming # steam = "*" # mobygames = "*" # Music # lastfm = "*" # discogs = "*" # Other # keybase = "*"
- またcontent/postのディレクトリに対して
hatena_2_hugo.rbで生成されたmdファイルを設置 themes/blackburn/layouts/partials/head.htmlをcanonicalurl変数を読み込めるようにheaderを修正- hugoのserverを起動し、ページが閲覧できるか確認
- http://localhost:1313/ を見てみるとページを確認することができる
$ cp ~/md_output/* content/post/ $ ls -la content/post | head -n 5 total 9624 drwxr-xr-x 208 yuta staff 6656 5 2 11:36 ./ drwxr-xr-x 3 yuta staff 96 5 2 11:36 ../ -rw-r--r-- 1 yuta staff 1926 5 2 11:37 201009060134.md -rw-r--r-- 1 yuta staff 15876 5 2 11:37 201009232329.md $ vim themes/blackburn/layouts/partials/head.html <!-- add canonical --> <link rel="canonical" href="{{ if .IsHome }}{{ .Site.Params.Canonicalurl }}{{ else }}{{ $.Params.Canonicalurl }}{{ end }}" /> $ hugo server -t blackburn -D -w ... Running in Fast Render Mode. For full rebuilds on change: hugo server --disableFastRender Web Server is available at http://localhost:1313/ (bind address 127.0.0.1)
Githubに登録し、Github Pagesを公開する
- Githubに登録する公開用静的ページを生成する。そうするとconfig.tomlで設定した
docsというディレクトリが作成される - Githubに登録不要なファイルを.gitignoreで設定する
- Githubにaddし、gh-pagesのbranchをremoteに反映
$ hugo -t blackburn $ ls docs total 1352 drwxr-xr-x 12 yuta staff 384 5 2 12:32 ./ drwxr-xr-x 12 yuta staff 384 5 2 12:26 ../ drwxr-xr-x 5 yuta staff 160 5 2 12:21 css/ drwxr-xr-x 3 yuta staff 96 5 2 12:21 img/ -rw-r--r-- 1 yuta staff 36870 5 2 12:32 index.html -rw-r--r-- 1 yuta staff 622268 5 2 12:32 index.xml drwxr-xr-x 4 yuta staff 128 5 2 12:21 js/ drwxr-xr-x 23 yuta staff 736 5 2 12:32 page/ drwxr-xr-x 210 yuta staff 6720 5 2 12:32 post/ -rw-r--r-- 1 yuta staff 28223 5 2 12:32 sitemap.xml drwxr-xr-x 4 yuta staff 128 5 2 12:32 startupai/ drwxr-xr-x 4 yuta staff 128 5 2 12:32 スタートアップaiに関わる内容を書きます/ $ cat .gitignore themes resources $ git add --all $ git push -u origin gh-pages
- 最後にgh-pagesのpull requestをmasterに反映。そうすると下記のURLでページを確認することができる。
- https://yutakikuchi.github.io/blog/
Github
- 今回作業した成果物を以下に配置
Docker for Macのメモリ制限の調整
Memory: By default, Docker Desktop for Mac is set to use 2 GB runtime memory, allocated from the total available memory on your Mac. To increase RAM, set this to a higher number; to decrease it, lower the number.
Docker for Macを使ってDocker runする際に --memory(-m) ではメモリの制限が指定できない。
Defaultの制限は2Gになっている。下記を実行しても10Gに反映されない
$ docker run -m 10g -i -t ubuntu /bin/bash
そこで、Desktopにある Preference -> Advance でMemoryの上限を調整する。Docker compose内でDeepLearningなどの重たい処理をしようとするとKilledになってしまう場合は、Memory不足であることが考えられるのでAdvanceの項目でMemory制限を解除する。下記はMemoryの制限を12Gに設定した場合。
